RNN 계열의 알고리즘에 대해 공부하다가 Attention mechanism에 대해 접하게 되었다. 하지만 대부분의 자료를 보고는 원리를 이해하기 매우 어려웠는데, 이를 이해하기 쉽게 설명해놓은 유튜브 영상을 접하여 정리하여 포스팅한다.
1. Attention mechanism 도입의 배경
기존 RNN 방식은 연속적인 데이터를 처리하는데 특화된 알고리즘으로서 각광을 받았지만, 몇가지 문제점을 가지고 있었다.

- Sequence로 입력을 모두 받은 후에 Decoding을 하는 방식이기 때문에 병렬화가 불가능하다.
- 고정된 크기의 Context 벡터에 모든 입력 값에 대한 정보를 압축하여 집어넣기 때문에 긴 데이터를 처리할 때 병목현상이 발생하여 정확도가 하락하게 된다.
- 관련 노드와의 거리가 멀어지면 Long-term dependency 특성에 의해 예측에 문제가 생긴다.
여기서 Long-term dependency 특성이란, 현재 Decoding하고 있는 영역과 그에 관련된 정보를 포함한 영역 간의 노드간 거리가 멀어질 경우, 입력 데이터의 특성이 일부 소실되었을 가능성이 커져서 그 특성을 제대로 반영하지 못하는 특성이다. 우리는 이러한 특성을 쉽게 접할 수 있는데, 주로 사용되는 분야인 번역 분야에서 굉장히 긴 문장이 입력으로 주어질 경우에 문장의 번역이 제대로 되지 않는 것이 이에 해당한다.
2. Attention mechanism이란?

Attention mechanism은 영상처리 분야에서 등장한 개념이다. 사람의 눈은 자신이 보고자 하는 것에 초점을 맞춰서 봄으로서 마치 필요한 정보에 가중치를 두고 처리하는 듯한 구조를 가진다. 카메라에도 이러한 기능이 탑재되어, 원하는 부분에 포커싱이 되고 기타 영역은 블러 처리가 된 사진을 쉽게 찾을 수 있다.

이러한 구조를 RNN 계열의 알고리즘을 활용하는 것에 활용하겠다는 것이 도입의 배경이며, 만약 문장을 번역하는 데에 활용된다면 지금 번역하고 있는 단어에 따라 어떤 입력된 단어에 "주목"할 지를 가중치로서 계산하여 활용하는 것이 Attention mechanism이다. Encoder에서 나온 각각의 RNN cell의 state를 반영하며, Decoder 내부에서 가변적인 크기를 갖는 Context 벡터를 생성하여 활용하기 때문에 입력 Sequence의 길이에 영향을 적게 받는다.
3. Attention mechanism의 작동 구조
Attention mechanism을 도입한 이후부터 대부분의 RNN 계열의 시스템에는 이를 활용하는 추세다. 하지만 Attention mechanism의 작동 방법을 이해하기 쉽지 않았는데, 유튜브에 잘 정리된 자료가 있어 빌려 사용한다. 허민석 유튜브 채널의 “[딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델“을 참고하였으며, 뒤에 링크를 추가하였다.
앞의 RNN을 번역 분야에서 사용하는 것을 예로 들었는데, 이번엔 Attention mechanism을 활용하여 번역하는 과정을 보이며 설명하겠다.

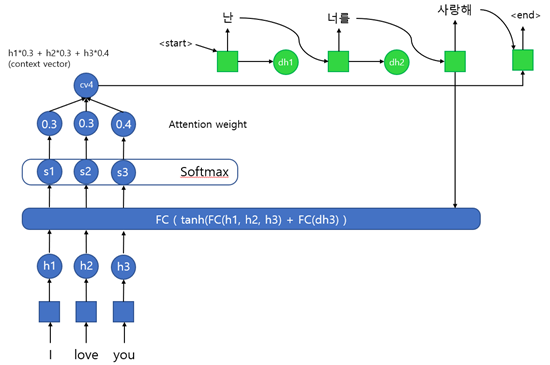
마찬가지로 입력으로 I love you라는 문장이 통째로 들어간다. 입력은 단어 단위로 히든 레이어를 통과시켜 h1, h2, h3 값을 구한다. 이 값들은 Alignment model의 입력 값으로 활용한다. 원래는 h1, h2, h3 값과 함께 이전 출력 값에 대한 정보인 dh 값이 입력으로 들어가야 하지만, 첫 번째 사이클에선 이전 출력 값이 존재하지 않기 때문에 h3 값을 입력으로 넣어준다.
Alignment model은 이 각각의 h1, h2, h3 값과 이전 출력 값과의 관계를 통해 어떤 단어에 집중하여 번역되어야 하는지에 대한 정보를 구하기 위해 작동한다. 때문에 내부를 살펴보면 Fully connected layer를 활용하여 유사도를 계산하는 것을 확인할 수 있다. 유사도를 구하기 위한 모델은 다양하게 존재한다고 한다. 계산되어 나온 이 유사도를 Attention score라고 한다.

이후 Attention score를 Softmax 함수를 활용하여 합이 1인 확률 값으로 만들어준다. 이 값을 Attention weight라고 하며 각 단어가 출력에 영향을 미치는 정도를 나타내는 가중치로 사용된다. (일부 블로그에서 이를 Attention score라고 하는 것을 봤는데, 이는 부르기 나름이기 때문에 크게 신경 쓰지 않아도 된다.)

각각의 Attention weight는 앞의 h1, h2, h3과 곱해진 후 합쳐져서 context vector를 구성한다. 즉, context vector는 각각의 사이클마다 다르게 계산되며, 크기에 제한이 없다는 것을 확인할 수 있다. 이 context vector는 이전의 출력 값(y)와 연결되어 비선형 함수를 통과하여 최종 출력 값을 계산하는데 사용된다.

첫 사이클에선 이전 출력 값이 없기 때문에 <start> 신호와 함께 연결되어 출력 값을 계산하는데 앞에서 현재의 출력과 연관이 가장 높은 단어가 “I” 였기 때문에 이를 번역한 “나”라는 단어를 배치하게 되고, start 신호로 현재 출력하는 자리가 주어 자리라는 정보를 받아 “난”으로 변환하여 출력하는 방식이라고 생각하면 이해하기 편하다.
최종 레이어의 출력은 다시 Alignment model에 입력으로 들어가며, 앞의 과정을 반복하게 된다.

이 과정을 거친 후에 작업이 완료되면 end값을 반환하고 작업을 마치게 된다. 아래의 그림은 어떤 단어끼리 관련이 있고 없는지에 대한 집중도를 plot한 그림이다. 이를 활용하면 특정 단어를 번역할 때 어떤 단어를 참고하여 번역해야 하는지에 대한 지표를 반영한 출력 값을 반환할 수 있다. 즉, Seq2Seq 네트워크의 긴 문장이 입력으로 들어왔을 때 처리하기 힘들다는 치명적인 단점을 극복하는데 활용이 가능하다.

4. Reference
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Minsuk Heo, “[딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델“, Google+, 2019.04.01 <https://www.youtube.com/watch?v=WsQLdu2JMgI>
'딥러닝 > 공부' 카테고리의 다른 글
| [Clustering Algorithm] KNN 알고리즘 (0) | 2021.12.07 |
|---|---|
| [영상 처리] Motion compensation(움직임 보상) (0) | 2021.05.21 |
| [Clustering Algorithm]밀도 기반의 DBSCAN Clustering (0) | 2021.05.20 |