딥러닝 네트워크는 높은 정확도를 위해 큰 연산 비용을 치룬다. 하지만 대다수의 사용자는 높은 정확도는 필요하지만 빠른 동작이 필수적이다.
이에 맞추어 Floating point으로 훈련된 최신 네트워크들을 Fixed point로 양자화하고 그 성능을 유지할 수 있다면 연산 속도가 빨라질 것이다.
제안된 PACT는 activation을 임의의 bit 정밀도로 양자화가 가능하며 일반적인 양자화보다 높은 정확도를 확보할 수 있다.
특히 가중치/활성화를 4bits 정밀도로 양자화할 수 있으며 성능은 Full precision과 유사한 동향을 보였다.
1. Primary Contribution:
최적 양자화 스케일을 찾을 수 있는 새로운 활성화 함수 양자화 기술인 PACT를 제안한다.
새롭게 도입한 α 파라미터는 활성화 함수를 클리핑하는 수준을 결정하기 위해 사용되며, 역전파를 통해 학습된다.
α는 양자화 오류를 줄이기 위해 ReLU보다 Scale이 작으며, 경사 흐름을 원활히 만들기 위해 전통적인 클리핑 활성화 함수보단 Scale이 크다.
빠른 수렴을 위해 Loss function에서 α는 정규화된다.
Extremely low bit-precision(≤ 2-bits for weights & activation)에서 PACT는 최고의 양자화 모델 정확도를 달성했다.
PACT에 의해 양자화된 4-bit CNN은 single-precision floating point 모델과 비슷한 정확도를 달성하였다.
다양한 bits 표현에 따른 하드웨어 복잡도와 모델의 정확도의 Trade-off 관계를 입증하고 분석한다. 또한, PACT의 컴퓨터 엔진 관점에서의 엄청난 효과를 보일 수 있음을 보이고 시스템 레벨에서의 성능 향상을 확인한다.
2.Challenges in Activation Quantization
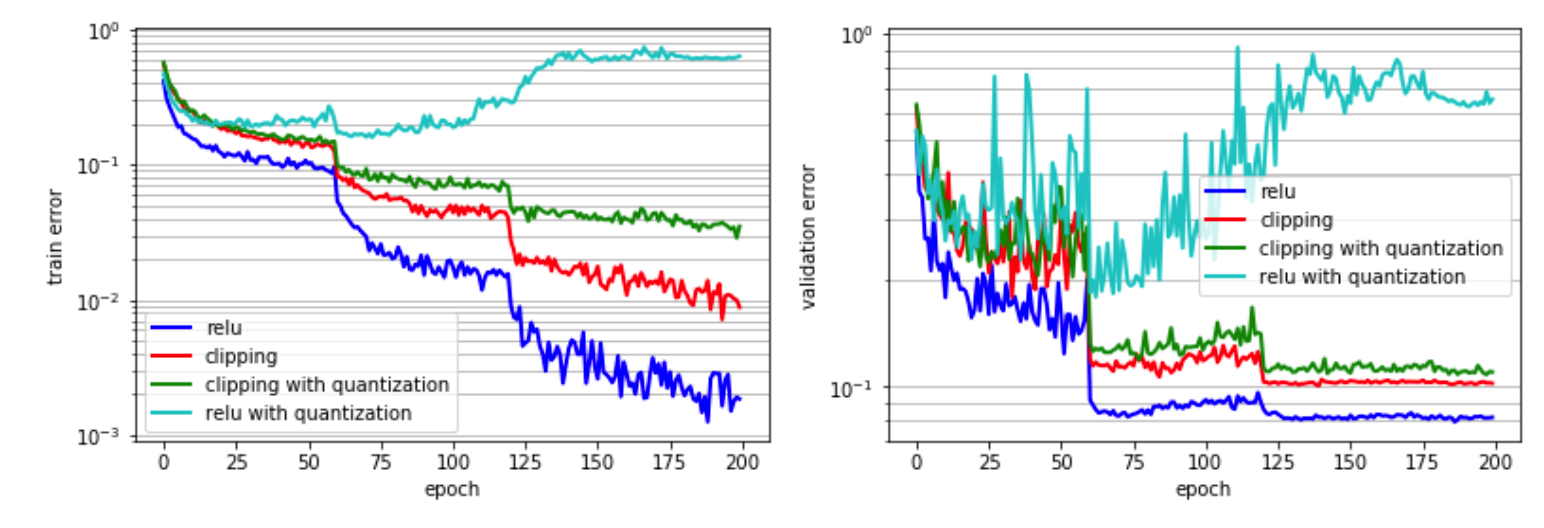
< Fig 1 > (a) 훈련 오류, (b) CIFAR10 데이터셋을 사용하는 ResNet20 모델에 대한 양자화/일반 ReLU/Clipping 모델 Validation error
가중치 양자화는 가중치과 관련된 Loss function의가설 공간을 이산화(discretizing)하는 것과 같다. 따라서 모델 훈련 중에 가중치 양자화 오류를 보상하는 것이 가능하다!
애석하게도 과거에 사용하던 활성화 함수는 훈련 가능한 파라미터를 가지고 있지 않았기 때문에 활성화를 양자화하면서 증가하는 에러를 역전파로 즉시 보상할 수 없었다.
이와 달리 ReLU는 활성화 기울기를 파라미터로 전파하여 다른 활성화 함수에 비해 우수한 정확도를 달성하기 때문에 훈련할 파라미터를 보유하고 있다. 하지만 ReLU의 출력은 (0,∞)이므로 ReLU 이후의 양자화를 위해선 엄청난 동적 범위(ex. more bit-precision)가 요구됐다. 그림을 봐도 양자화된 relu의 성능이 매우 떨어짐을 확인할 수 있다.
이러한 동적 범위(High dynamic range) 문제는 threshold(upper bound)를 주는 방식인 clipping을 사용하여 어느정도 해결 가능하다. 하지만 레이어 마다, 모델마다 최적의 전역 Clipping 값을 결정하기 매우 어렵다. 그림을 확인해보면 clipping을 함께 활용했을 때 relu에 양자화를 적용했을 때보단 오류가 줄었지만 아직도 baseline 보단 오류가 큰 것을 확인할 수 있다.
3.PACT: Parameterized Clipping Activation Function
PACT에서는 Clipping level을 설정하는 α가 존재한다. α는 양자화로 인해 발생한 정확도 감쇠를 줄이기 위한 목적으로 역전파를 통해 훈련 간에 동적으로 교정된다.
α가 클수록 매개변수화 된 Clipping 함수가 ReLU와 비슷해진다. 넓은 동적 범위로 인한 큰 양자화 오류를 방지하기 위해여 α에 대해 L2-정규화를 적용한다. Fig2는 완전 정밀 훈련 간 초기값 10에서 시작했을 때 L2-정규화를 적용하면 α 값이 어떻게 변하는지 보여준다. 훈련 apoch에 따라 α가 훨씬 작은 값으로 수렴하여 활성화의 범위를 제한하고 손실을 최소화하는 것을 확인할 수 있다.
< Fig 2 > CIFAR10 데이터셋+ResNet20을 사용한 훈련 중 α 값의 변화.
3.1. Understanding How Parameterized Clipping Works
Fig.3은 사전 훈련된 SVHN 네트워크에서 α 범위에 대한 교체 엔트로피 및 훈련 소실을 보여준다.
모델에서 7개의 각 conv 레이어에 대한 활성화 함수 ReLU가 제안된 clipping ActFN으로 대체된 제안된 양자화 방식으로 훈련된다. 교차 엔트로피를 계산할 때는 현 레이어의 α를 제외한 모든 파라미터를 고정한 상태로 한 번에 한 레이어씩 α 값을 수정한다.
양자화 없이 계산된 교차 엔트로피는 Fig 3. (a)에 나와있다. 이는 α=∞와 같고, 교차 엔트로피는 α가 증가함에 따라 많은 레이어에서 작은 값으로 수렴된다는 사실을 확인할 수 있다. (ReLU는 좋은 활성화 함수임을 다시한 번 확인할 수 있다)
그러나 α를 훈련하면 특정 레이어에 대한 교차 엔트로피를 줄일 수 있을 것 역시 예상할 수 있다. act0과 act6의 그래프를 보면 튀는 모습을 보이기 때문이다.
다음으로 양자화 된 교차 엔트로피는 Fig3. (b)에 나와있다. 양자화를 사용하면 대부분 α가 증가함에 따라 교차 엔트로피가 증가하여 ReLU의 성능이 떨어짐을 볼 수 있다. 또한 최적의 α가 레이어마다 다른 것을 관찰할 수 있는데, 훈련을 통해 양자화 Scale을 학습한다면 해당 문제를 해결할 수 있을 것이다. 또한, 특정 범위에 대해 교차 엔트로피가 높은 엔트로피에 수렴(act6)하는 것을 확인할 수 있는데, 이는 경사하강법 기반 훈련에 문제를 일으킬 수 있다.
마지막으로, Fig 3. (c)에서는 교차 엔트로피와 α 정규화 학습을 모두 사용한 총 훈련 손실을 보여준다. 정규화는 훈련 손실의 안정화 수렴을 효과적으로 제거하여 경사하강법 기반 훈련에 효과적인 수렴을 일으킨다. 동시에 α 정규화는 전역 최소점을 확실하게 한다. 그림을 보면 훈련 손실 커브상의 최적 α 값에 점을 확인할 수 있다.
3.2. Exploration of Hyper-Prarmeters
3.2.1. Scope of α
저자는 총 세 가지 케이스를 비교하였다.
뉴런 활성화 별 개별적인 α 값
같은 출력 채널을 가지는 뉴런 사이에서 공유되는 α값
레이어에서 공유되는 α값
CIFAR10+ResNet20으로 실험한 결과 세 번째 케이스가 가장 높은 성능을 보였다. 이는 하드웨어 복잡도 측면에서도 레이어에서 Multiply-accumulate(MAC) 연산 이후 α가 한 번만 곱해지므로 더 좋은 결과를 보인다.
3.2.2. Initial Value and Regularization of α
α가 매우 작은 값으로 초기화되면 더 많은 활성화가 0이 아닌 기울기 범위에 들어가, 훈련 초기에 불안정한 α값을 만들 가능성이 있고 정확도를 하락시킬 수 있다.
그렇다로 α가 매우 큰 값으로 초기화되면 기울기가 너무 작아지고 α가 큰 값으로 고정되어 잠재적으로 양자화 오류가 더 커질 수 있다.
따라서 넓은 동적 범위를 가지고 불안정한 α값을 피하기 위하여 적당히 큰 값으로 α를 초기화하고, 양자화 오류를 완화하기 위하여 α값을 정규화하는 작업이 필요하다.
실제로 α에 대해 L2-정규화를 적용할 때 계수 가중치를 α에도 동일하게 적용할 수 있다. Fig. 8을 보면 PACT 양자화 검증 오류가 넓은 범위의 가중치(λ) 값에 대해 크게 별화지 않는 것을 확인할 수 있다.
4. Experiment
그림을 보면 training/validation error가 full-precision과 비슷하다는 것을 확인할 수 있다.
또한, 표에서 볼 수 있듯이 DoReFa와 비교했을 때 더 높은 성능을 보였으며, 4bits 양자화를 PACT로 수행했을 때, full-precision과 성능이 비슷하거나 심지어 더 좋게 나온 케이스도 존재했다.
중요한 것은 가장 낮은 bit 정확도에서도 full-precision 대비 1% 이하의 성능 하락만이 발생했다는 점이다.
예를 들어, 나는 딥러닝 네트워크들 중 YOLOv2를 MATLAB 상에서 KITTI dataset으로 훈련시켰고 이를 KITTI에서 제공하는 다른 데이터셋(ex Tracking dataset) 등에서 검증하였다. 하지만 다른 데이터셋에서도 높은 성능을 보일 수 있는지 궁금했고 자율주행을 위한 훈련 데이터셋으로 유명한 BDD를 활용하고자 했다.
Berkley DeepDrive dataset에서 tracking dataset은 JSON 파일 형식으로 지원되며, 총 10개의 클래스로 분류된다. 현재 Sequence 상황에서의 성능 향상에 관련된 연구를 진행하고 있기 때문에 구현한 코드를 검증하기 위하여 해당 데이터셋을 활용하기로 결정하였고, 이를 위해서는 MATLAB에서 사용가능한 형태로로 변환할 필요가 있었다.
직접 파일을 구현하는건 매우 귀찮은 과정이기 때문에 관련 자료를 찾아봤지만 찾지 못했고 어쩔 수 없이 손수 코딩해야 했다. 다른 사람은 이런 과정을 거치지 않았으면 해서 구현한 코드를 구현한다.
JSON 파일 내부에 있는 데이터를 2D 객체 검출에서 활용하는 Bounding box(x, y, widty, height) 꼴로 변환해야 하며 이를 table 형태로 변환하여 활용한다.
function MakeClasscell = mcc(arr)
MakeClasscell = {};
if ~isempty(arr)
for l = 1:size(arr, 1)
sav = [];
for k = 1:size(arr,2)
if ~isempty(arr{l,k})
sav(size(sav,1)+1,1:4) = arr{l,k};
else
continue
end
end
MakeClasscell(l,1) = {sav};
end
end
end
2. 코드 설명 & 추가 활용법
input으로는 라벨의 경로를 넣어주면 된다. 이 파일을 사용할 때 주의해야 하는 점은 세 가지이다.
함수를 사용할 때는 파일의 확장자까지 넣어주어야 한다는 점을 기억해야 한다. BDD dataset의 라벨은 json 파일으로 제공되므로 'C:\User\users\...\abcd02020.json'와 같은 형식으로 함수의 인자에 넣어준다.
mcc 함수 역시 github에 함께 올려 놓았으니 다운 받아서 사용하면 된다.
20번째 줄의 코드는 사용자에 따라 다를 수 있으니 이미지가 존재하는 폴더 경로로 변경해야 한다. (fname = strcat(fname(1:11),'images\track\train', fname(37:54));)
이를 활용해서 생성되는 것은 table 형식이며 이를 활용한 훈련이나 검증이 모두 가능하다. 하지만 혹여나 ground truth 형식으로 변환하고 싶다면(예를 들어, 훈련에 ground truth 형식의 변수가 필요하거나 image labeler 확장 앱으로 시각화하여 확인하고 싶다면) 아래의 코드로 ground truth 형식으로 변환할 수 있다.
Gao, Chen, Yuliang Zou, and Jia-Bin Huang. "ican: Instance-centric attention network for human-object interaction detection." arXiv preprint arXiv:1808.10437(2018).
1. Abstract
사진을 보고 그 장면을 이해했다고 말하기 위해선 사람과 그 주변 물체가 어떤 상호작용을 하고 있는지에 대해 설명할 수 있어야 한다. 본 논문에서는 HOI(Human-object interactions)를 추론하는 작업을 주로 다루었다.
각 영역의 형상(appearance)에 interaction을 예측하기 위해 주의 깊게 확인해야 할 영역에 대한 정보가 포함되어 있다. 이를 Attention map이라고 하며, 본 논문에선 이 영역을 강조하는 방법을 학습할 수 있는 모듈을 제안하였으며 이를 활용하여 전체 Context를 예측한다.
2. Introduction
Why HOI?
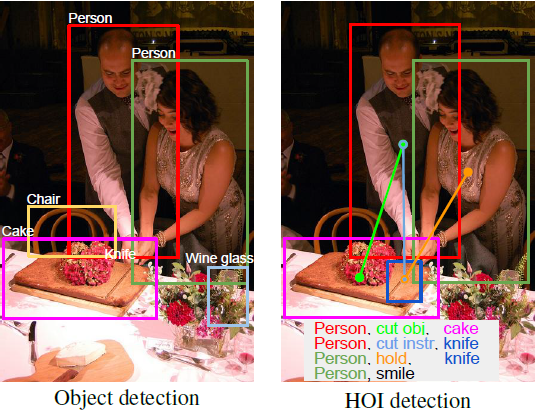
위의 그림을 통해 HOI의 역할을 쉽게 이해할 수 있다. 입력 이미지와 감지기(Detector)에서 감지된 Attention region이 주어지면 이미지 내부의 모든 [사람, Verb(행동), 물체]의 triplet을 식별하는 것을 목표로 한다.
HOI는 "어디에 무엇이 있는가?"의 관점이 아닌 "무슨 일이 일어나고 있는가?"에 초점을 맞춘 작업이라고 생각하면 이해가 편하다. 해당 기술을 연구하는 것은 Pose estimation, Image captioning, Image retrieval 등의 높은 수준의 작업에 대한 단서로 작용할 수 있다.
Why Attention map?
최근 연구에선 사람과 물체의 형상이 어떤 영역에 관련이 있는지를 활용한다. 즉, 사람의 외형적 특징과 함께 동작을 인지하는 알고리즘을 사용한다면 더 정확한 문맥 추론이 가능할 것이다.
예를 들어 위의 사진을 살펴보면 Context를 추측하기 위한 다양한 알고리즘들이 소개되어 있다. Secondary regions의 활용, 사람과 물체의 바운딩 박스의 결합 사용, 사람의 포즈의 키포인트 주변의 Feature 추출 등이 활용될 수 있다.
이와 같은 방법들로 추출된 Context를 통합하여 Attention map을 구성한다면 당연히 성능이 향상될 것이다. 하지만 이 방식은 딥러닝으로 자동화 된 Attention map을 예측하는 기술이 아니며 사람이 직접 Attention region을 설정하는 방식이다. 이렇게 생성된 Map은 동작/상호작용을 인지하는 작업에 완벽할 수 없다. 상황마다 집중(Attention)할 영역이 달라지기 때문이다.
예를 들어, '던지기'나 '타기'와 같은 동작을 식별하기 위해선 사람의 자세를 봐야할 것이고, '컵으로 마시기', '숟가락으로 먹기'와 같은 손과 물체의 상호작용과 관련된 동작을 인식하기 위해선 상호작용에 초점을 두어야 하며, '라켓으로 공을 치는 것'이나 '배트로 야구공을 타격하는 것'은 전체적인 배경에 집중해야 할 것이기 때문이다.
최근 연구에서는 위의 한계를 해결하기 위하여 행동 인식 또는 이미지 분류를 위해 훈련 가능한 end-to-end Attention 모듈을 활용한다. 하지만 이러한 방법은 인스턴스 수준이 아닌 이미지 수준의 분류 작업을 위하여 설계되었다.
3. Instance-Centric Attention Network
본 논문에선 HOI scores를 다음과 같은 식으로 계산한다.
$S^a_{h,o}$ : HOI score
$s_h, s_o$ : FasterRCNN으로 검출된 사람과 물체의 Confidence score
$s^a_h, s^a_o$ : 검출된 형상(appearance)에 기반한 사람과 물체의 interaction score [Object/Human stream]
$s^a_{sp}$ : 사람과 물체 사이의 spatial 관계에 기반한 interaction score [Pairwise stream]
$s_h$는 FasterRCNN으로 검출된 사람의 confidence score이며 $s_o$는 물체의 confidence score이다. 사람의 행동을 예측할 때 웃는 사람 등 물체가 없는 경우도 검출할 수 있어야 하는데, 이 상황에서 HOI scores는 $S^a_{h,o} = s_h \centerdot s^a_h$가 된다.
3.1 Instance-centric attention module
해당 모듈에선 FasterRCNN을 활용하여 생성한 Feature map(FM)을 활용하여 Context를 뽑아내는 과정이 이루어진다. 우선 FM에서 ROI pooling, res5 block, Global average pooling을 거쳐 인스턴스 레벨의 사람의 형상인 $x^h_{inst}$를 추출한다.
추출된 $x^h_{inst}$는 FC layer를 통과하여 512-dimensional 벡터가 되어 다시 FM과 dot production을 수행하여 유사도를 계산한다. 이후 softmax를 적용하여 Attentional map을 추출할 수 있다.
이 Attentional map과 기존 이미지를 dot production하면 HOI 작업에 활용할 수 있는 highlighting된 map을 구할 수 있다. 결과 값 역시 GAP를 거치고 FC 레이어를 거쳐 $x^h_{context}$ context 벡터를 만들며 이는 앞에서 구한 인스턴스 레벨의 $x^h_{inst}$ 벡터와 연결되어 사용된다.
이 벡터를 활용하여 $s^a_h, s^a_o$를 구할 수 있다.
이렇게 구성된 iCAN 모듈은 두 가지 장점이 있는데,
첫째, 다양한 알고리즘을 적용한 결과를 토대로 손으로 설계해야만 하는 Attention map과 달리 자동으로 Attention map을 생성하고 성능 향상을 위해 훈련될 수 있다.
둘째, image-level의 모듈과 비교하였을 때 instance-centric attention map은 다른 영역에 더 주의를 기울일 수 있으므로 더 유연한 활용성을 보인다.
3.2 Multi-stream network
위의 그림을 보면 네트워크는 총 세 가지 stream(object, human, Pairwise stream)로 구성되어 있는 것을 볼 수 있는데, 3.1에서 본 과정이 Object/Human stream에 해당하는 과정이며 binary sigmoid를 통과시켜 최종 HOI score를 계산하기 위한 식에서 $s^a_h$와 $s^a_o$를 계산할 수 있었다.
Pairwise stream에서는 two-channel binary image representation을 채택하여 상호작용 패턴을 추출한다. 사람과 물체의 바운딩 박스의 합집합을 reference box로 활용하여 그 안에서 두 개의 채널을 활용하는 방식이다. 첫 번째 채널은 사람 바운딩 박스 안에서 값 1을 가지며 다른 곳에서는 0을 갖고, 두 번째 채널은 물체 바운딩 박스 안에서 값 1을 가지며 다른 곳에서는 0을 갖는다. 그 후 CNN을 활용하여 이 2채널 이진 이미지에서 spatial feature를 추출한다.
하지만 이 작업만으로는 정확한 동작 예측이 불가능하므로 인스턴스 레벨의 사람의 형태인 $x^h_{inst}$와 연결하여 binary sigmoid를 통과시켜 $s^a_{sp}$를 구한다. 그 이유는 사람의 형태가 비슷한 레이아웃(예를 들어 자전거를 옮기는 사람과 자전거를 타는 사람)에서 다른 행동을 판단하는데 도움이 되기 때문이다.
Motion compensation은 연속된 영상의 두 프레임의 차이가 카메라가 움직이거나 물체가 움직인 결과라는 사실을 활용한다. 이는 한 프레임을 나타내는 정보들이 다음 프레임에서 사용되는 정보와 동일함을 의미한다.
움직임 보상은 대부분의 동영상 압축 기술(MPEG-2 등)에 적용되고 있는 기술이다. 현재의 영상을 부호화하기 위하여 기존의 부호화 된 영상을 가져와서 예측을 하기 위하여 사용된다. Motion Estimation은 Motion compensation을 위해 Motion vector를 찾는 기술을 의미한다. 이와 비슷하게 비디오를 압축하는 기술은 Discrete Cosine Transform(DCT)이 있다.
아래의 내용은 Wikipedia를 참고하여 작성되었다.
2. 기능
Motion compensation은 보통 두 개의 연속된 프레임의 차이를 Difference map으로 추출하고 해당 map을 활용하여 이전 프레임과 현재 프레임 간의 shift vector를 재추출하여 Motion compensated difference map을 구한다. 두 프레임 간의 움직임 벡터만을 뽑아낸 MCD map은 이미지 자체를 활용하는 것보다 더 적은 정보를 담고 있으므로 이를 활용하면 영상의 압축이 가능하다. 따라서 보상된 프레임을 인코딩하는데 필요한 정보는 Difference map보다도 훨씬 작다.
출처: 위키피디아
3. Global Motion Compensation(GMC)
Motion 모델은 기본적으로 다음과 같은 카메라 움직임 특성들을 반영한다.
Dolly: 카메라를 앞뒤로 이동
Track: 카메라를 왼쪽 또는 오른쪽으로 이동
Boom: 카메라를 위 또는 아래로 이동
Pan: Y축을 기준으로 카메라 회전, View를 좌우로 이동
Tilt: X축을 기준으로 카메라 회전, View를 위아래로 이동
Roll: Veiw(Z) 축을 기준으로 카메라 회전
해당 보정 과정은 물체가 없는 스틸씬에 적합하며, 몇가지 장점을 가지고 있다.
몇 개의 파라미터만 가지고 비디오 시퀀스에서 주요 움직임들을 모델링이 가능하다. 파라미터들의 비트 전송률 점유율 자체는 무시가 가능하다.
프레임을 분할하지 않기 때문에 흔적이 남지 않는다.(여기서 artifacts를 흔적으로 의역하였음. artifacts가 존재할 경우 연속성 X)
프레임에서 시간축에 해당하는 직선을 따라 실제 영상은 연속적으로 움직인다. 다른 Motion compensation 체계는 시간 방향에 불연속하다.
MPEG-4 ASP(코덱이라고 보면 될듯)은 세 개의 참초 포인트가 있는 GMC를 지원하지만 보통 하나만 사용 가능하다. 단일 기준점을 사용하면 상대적으로 큰 성능 비용이 발생하여 뒤에 나올 Block motion compensation에 비해 거의 이점이 존재하지 않는다. 또한, 프레임 내에서 움직이는 물체를 표현할 수 없기 때문에 Local motion estimation도 필요하다는 단점이 존재한다.
4. Motion-compensted DCT
Block motion compensation(BMC)은 motion-compensation discrete cosine transform(MC DCT)라고도 하며, Motion compensation 테크닉으로 가장 많이 사용된다. BMC는 프레임을 이미지의 픽셀들을 블록을 나누는 방식을 활용한다.(예를 들어 MPEG에서는 16x16 픽셀 사이즈의 macro-block을 사용함) 각각의 블록은 기준 프레임에서 동일한 사이즈의 블록으로부터 각각의 블록들의 움직임을 예측한다.
인접한 블록 벡터들이 단일 이동 객체에 그려지게 되면 해당 벡터들은 중복되는 성질을 갖게된다. 이를 활용하기 위해 비트스트림(bit의 시계열)에서 현재 및 이전 Motion vector 간의 차이만 인코딩하는 것이 일반적이다. 이 과정의 결과는 패닝이 가능한 글로벌 움직임 보정과 수학적으로 동일하다. 인코딩 파이프라인 뒤에서 엔트로피 인코더는 출력 크기를 줄이기 위하여 영벡터 주변의 움직임 벡터에 대한 통계적인 분포를 활용한다.
정수가 아닌 픽셀 수만큼 블록을 이동할 수 있기 때문에 하위 픽셀 정밀도라고 한다. 중간 픽셀은 인접 픽셀을 보간하여 생성되며, 일반적으로 절반 픽셀 또는 1/4 픽셀 정밀도가 사용된다. 보간에 들어가는 연산량과 인코더에서 평가할 소스 블록 수가 많기 때문에 서브 픽셀 정밀도의 계산 비용이 훨씬 더 크다.
BMC의 주요 단점은 불연속성을 도입한다는 것이다. 블록으로 인해 블록 가장자리가 수평/수직 모서리로서 사람의 눈에도 쉽게 감지되고 푸리에 변환 계수의 양자화(quantization)로 인해 edge 현상 및 Ringing 현상이 발생한다.
BMC는 현재 프레임을 겹치지 않는 blocks로 나누고 motion compensation vector로 부터 이 블럭들이 이전 프레임의 어디서 왔는지, 어디로 이동할지를 알 수 있다.
추가로 삼각형 타일을 Motion compensation에 활용하는 방법도 제안되었다. 프레임은 삼각형으로 타일화 되고 다음 프레임은 이 삼각형들의 아핀 변환으로 생성된다. 이 과정에서 Affine 변환만이 기록/전송되며 확대/축소, 회전, 변환 등을 처리할 수 있다.
DBSCAN(Density-Based Spatial clustering of applications with noise)은 대표적인 밀도 방식의 클러스터링 기법이다. 군집 간의 거리를 이용하여 클러스터링을 하는 대표적인 알고리즘은 K-means와는 달리, 밀도를 호라용한 클러스터링은 점이 모여있는 영역을 합쳐나가는 방식이다.
각 점 데이터가 2D/3D로 흩뿌려져 있다고 가정하면 상태는 아래와 같다. 아래와 같은 데이터를 DBSCAN 알고리즘을 활용하여 클러스터링 하기 위해선 두 가지 파라미터 $\epsilon, n$을 설정해야 한다.
epsilon으로 인접하다고 판단하고 점군 데이터를 묶어줄 바운더리를 설정한다. (좌) 처리 전 점군 데이터, (우) 설정한 epsilon 데이터로 생성한 바운더리
$\epsilon$은 처리할 벡터로 부터 인접한 벡터들을 묶기 위한 거리 파라미터라고 생각하면 편하고, $n$은 해당 거리인 $\epsilon$ 안에 point가 몇 개가 있을 때 함께 묶어서 군집화 할 지를 정하는 개수 파라미터이다.
위의 두 가지 파라미터를 설정하였다면 DBSCAN Clustering을 진행할 수 있다. 해당 알고리즘을 수행할 때 벡터를 분류하는 기준은 총 4가지가 존재한다.
인접 벡터 : 현재 처리하고 있는 Point에서 $\epsilon$ 반경을 갖는 원을 그렸을 때, 그 원 내부에 존재하는 점 벡터
Core point : 자신을 포함한 인접 벡터의 수가 $n$개 이상인 점 벡터
Border point : 가장자리 벡터라고 생각하면 편하며, Core point에 연결되어 있으나 자기 자신은 Core point가 아닌 점벡터
Noise point : 다른 Core point와 연결도 되지 않고, 자기 자신도 Core point가 아닌 점벡터
또한 클러스터링을 진행할 때 적용되는 특성은 두 가지가 존재한다.
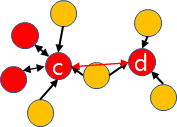
Density-reachable : Core point a와 a와 연결된 인접 벡터 b에 대하여 b는 a에 접근 가능하다. 하지만 b가 Core point가 아닌 경우엔 a에서 b로는 접근이 불가능하다.
Density-connected : 어떠한 점벡터 c와 d에 대하여 c와 d에 접근 가능한 벡터 v가 존재할 때, c와 d는 서로 연결되어 있다.
2. 알고리즘 진행 과정
위의 특성들을 모두 반영하여 클러스터링은 아래와 같이 진행된다.
여기서 Density-connected 특성까지 반영하면 최종 클러스터링 결과는 아래와 같다.
3. 결론
DBSCAN 알고리즘은 주어진 데이터들에 대해 각각의 데이터들을 세 가지(Core, Border, Noise)로 분류하는 것으로 K-Means Clustering에 비교해봐도 상당히 명확한 기준을 가지고 있는 것을 볼 수 있다. 실제로 각각의 데이터들을 분류하기 위한 거리인 $\epsilon$ 내의 데이터들의 숫자를 파악하고 또한 그 데이터들을 추가 분류함으로서 순차적으로 분류해나갈 수 있다.
K-Means와 비교하여 DBSCAN은 군집의 개수를 정의할 필요도 없으며, 군집의 형태에 영향을 받지 않는다. 또한 Noise를 따로 분류하고 영향을 받지 않기 때문에 더욱 명확한 분류가 가능하다.
하지만 다양한 밀도를 가지는 데이터의 분류에 적합하지 않고, 고차원 데이터에 대해서 적절한 $\epsilon$ 값을 찾기 어렵다는 단점도 존재한다.
적합한 $\epsilon$ 값은 k-distance graph를 활용하여 구할 수 있다. 좋은 $\epsilon$ 값은 묶인 데이터들끼리 강력한 기준에 부합되게 분류되는 값이며, 극단적으로 크면 한 군집만이 만들어지고 작으면 대부분의 데이터가 클러스터링 되지 않을 것이다. 아래의 사진은 출처의 블로그에서 다양한 밀도의 데이터에 대해 DBSCAN Clustering 작업을 수행한 결과이다. 밀도가 높은 곳에 집중하기 때문에 밀도가 낮은 곳을 하나의 클러스터로 인식하지 못하고 노이즈로 처리한 모습을 볼 수 있다.
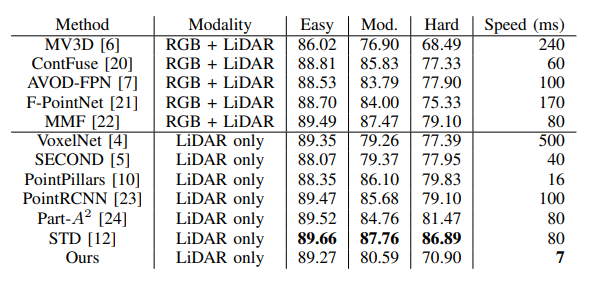
자율주행에는 주행 중에 마주칠 수 있는 다양한 물체들의 종류를 판별하고 그 물체까지의 거리를 파악하여 차량을 동역학적으로 제어하는 능력이 필요하다. 보통 자율주행의 3요소라고 함은 Perception, Control, Localization & Mapping를 의미하는데 이 기능들이 모두 정확하게 기능해야만 완벽한 자율주행이 가능하다. 딥러닝은 모든 분야에 적용이 가능하지만 보통 이미지나 데이터로부터 라벨을 예측하는 분야는 Perception에 해당한다.
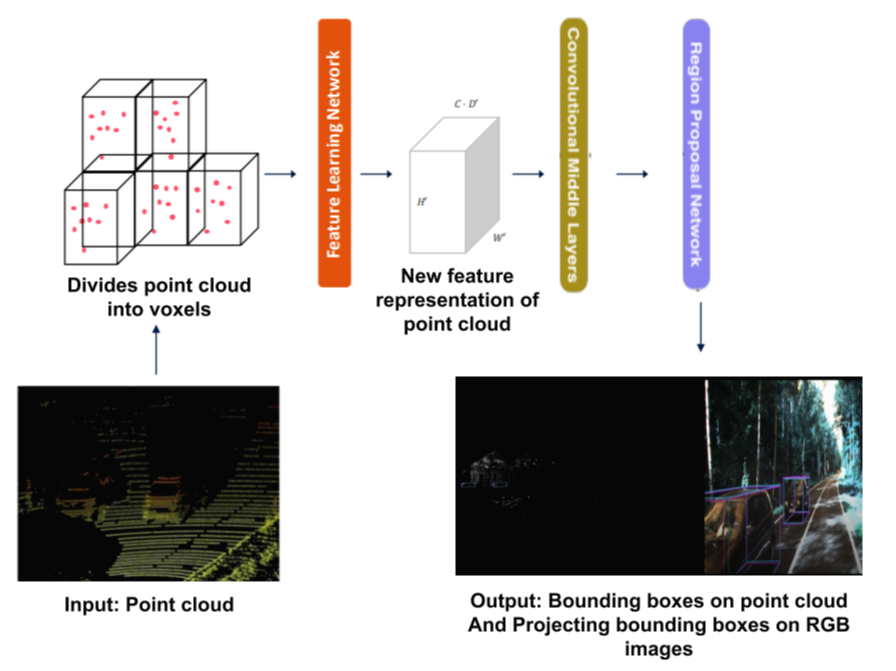
해당 논문은 차량에 탑재되는 LiDAR를 활용하여 다중 클래스 감지와 주행 가능 영역을 감지가능한 2-Stage DNN 알고리즘을 소개한다. 기존 알고리즘들은 Voxel 구조가 3D이기 때문에 3D Convolution을 활용해왔고, 이 때문에 많은 파라미터를 학습시키고 활용해야 해서 높은 FPS를 얻기 힘들다고 알고 있었는데, 실시간 처리를 강조한 논문이란 점이 인상적이었다. 2020년 IROS 컨퍼런스에서 발표된 논문이고, 현재까지 인용수는 3회이다.
1. Introduction
전통적으로 다양한 물체를 감지하고 해당 물체까지의 거리를 취하기 위해서 RGB 이미지와 LiDAR 데이터를 동시에 활용하는 방법을 활용해왔다. RGB 이미지는 물체의 Class를 판별하는 것에 강점을 가지고 있고, LiDAR 데이터는 물체까지의 거리를 판별하는 것에 강점을 가지고 있기 때문이다. 하지만 RGB 이미지는 카메라를 활용하여 3D World를 2D image에 투영하는 방식으로 제작되어 기하학적으로 부정확한 문제가 발생한다. LiDAR는 이러한 문제를 해결 할 수 있지만 3D 포인트 클라우드를 처리하는 데에 문제를 가지고 있다.
이를 해결하기 위하여 3D 포인트 클라우드를 3D Voxel grids로 처리하곤 하지만 연산량이 너무 높고 처리 과정에서 양자화 오류가 발생한다. 또다른 방법은 BEV(Bird Eye's View)에 투영하여 처리하는데 이 방식은 보행자의 크기가 너무 작아져서 정보의 손실이 발생한다.
3D Voxel girds: LiDAR 데이터는 일반적으로 point clouds를 모두 처리하기엔 연산량이 너무 방대하기 때문에 Point clustering 혹은 voxel 방식으로 전처리를 해준다. 여기서 Voxel이란 체적을 의미하는 것으로 3D 영역을 Voxel grid로 쪼개어 점군 데이터를 묶어주는 역할을 의미한다.
이 논문에서 제시한 내용을 정리하면 아래와 같다.
두 개의 서로 다른 View를 활용하여 LiDAR 입력을 처리하는 단일 네트워크로 차량과 보행자를 감지할 수 있고 주행 가능 영역을 감지할 수 있는 Multi-View Multi-Class 시스템을 제안
단순한 구조를 활용하여 해당 시스템은 임베디드 GPU에서 150fps로 매우 빠른 속도로 동작한다.
결과 값은 프레임 당 100대 이상의 자동차와 사람들이 표시된 매우 도전적인(extremely challenging) 데이터 환경에서 시연되므로 최첨단 자율주행 LiDAR perception 분야에 진보를 가져올 수 있다.
2. Related Works
[1] PIXOR는 2D Convolution을 활용하여 Multi-channel BEV tensor로 투영된 LiDAR Point Clouds에서 객체를 감지한다. 네트워크는 Confidence map을 연산하고 각 출력 픽셀에 대한 Bounding box의 위치, 크기 및 방향을 Regression한다. Bounding box는 Clustering 과정으로 추출된다. 이러한 방식은 빠르지만 보행자와 같은 물체는 BEV에서 다른 물체와 구별이 힘들기 때문에 오검출 문제가 발생한다.
[2] Fast and Furious는 동시 감지, Object tracking, 동작 예측을 다룬다. 접근 방식은 PIXOR과 비슷하지만 일부 버전은 Voxel화 된 Point clouds(4D tensor)에 적용된 3D Convolution을 사용하기 때문에 느리다. 또한 결과는 자체적인 데이터셋에 대해서만 제시되었다.
[3] VoxelNet은 밀도가 높은 복셀을 만들기 위해 무작위로 서브샘플링된 3D LiDAR Point clouds를 Voxelize한다. RPN이 3D 객체 감지를 위해 사용되고 복셀은 3D 텐서로 변환된다. 이로 인해 실행 시간은 느려지고, 복셀화 단계에서 정보 손실이 발생한다.
# Random Sub-sampling이란?
LiDAR Data를 전처리하기 위해서 Voxel grids로 쪼개기 전에 랜덤으로 일부 Points만을 뽑아내는 과정을 Random Sub-Sampling이라고 한다.
샘플링 된 데이터는 정육면체 꼴을 띄는 Voxel에 의해 묶이게 되며 Voxel의 크기가 클 수록 점 군의 개수가 줄어든다. 해외 블로그 중 정리가 잘 된 자료가 있어서 가져와봤다.
Random sub-sampling은 전체 데이터를 활용할 필요가 없을 때 연산량을 줄이기 위해 사용된다.이후 사전 정의된 voxel에 의해 grid 방식으로 묶이고 각각이 하나의 point cell로 정의된다. (자료 출처 : https://ichi.pro/ko/python-eulo-lidar-pointeu-keullaudeu-cheolileul-jadonghwahaneun-bangbeob-176090526667628)
[4] SECOND는 point clouds를 Voxel feature 및 좌표로 변환하여 sparse Convolution을 적용한 후 RPN을 적용한다. 정보는 3D 데이터를 다운 샘플링하기 전에 Point Clouds에서 수직으로(vertically 추출된다.) 런타임은 개선되었지만 Voxelize 단계에서 정보 손실은 여전히 발생한다.
[5] MV3D는 Point clouds를 높이 맵과 intensity를 나타내는 여러 채널이 존재하는 다중 채널 BEV로 변환한다. 정확도를 높이기 위해 LiDAR 및 RGB 카메라 데이터를 모두 활용하며 Perspective view를 이미지에 결합하고 Region proposal이 3D 감지에 사용된다.
[6] AVOD 역시 LiDAR와 RGB를 모두 사용하며, FPN 및 RPN에 기반한 새로운 Feature 추출기를 활용하여 물체를 감지한다.
[7] PointNet은 3D Point clouds에서 직접 작동하는 객체 분류 및 포인트 별로 Semantic segmentation을 수행한다.
[8] PointPillars는 LiDAR Point clouds만 사용하고, PointNet을 활용하여 Point clouds를 Column로 구성함으로써 높은 성능과 속도를 동시에 달성한다. 네트워크는 포인트를 인코딩하고 단순화 된 PointNet을 실행하고 SSD(Single Shot multi object Detector)를 사용하여 물체를 감지한다.
[9] STD는 Point clouds의 semantic segmentation을 위한 PointNet++와 분류/회귀 예측을 위한 proposal generation network의 2 Stage를 활용한다.
[10] Lidar DNN은 이 논문과 같은 방식으로 Point clouds의 Perspective view 및 BEV를 사용한다. Bounding box는 supervision target으로 사용되며 네트워크는 두 병렬 구조로 2D Convolution을 활용하여 각 View에서 특징을 추출하는 방법을 학습한다. 결과는 단일 클래스 객체 감지를 보인다. (MVLidarNet은 다중 클래스 객체 감지를 수행하고 더 빠른 감지를 보임)
[11] RangeNet++는 2D semantic segmentation 네트워크가 적용되는 ego-centric 범위의 이미지에 point clouds를 구형으로 투영한다. k-nearest neighbor(kNN) 후처리가 투영되지 않은 분할된 point clouds에 적용되어 인접 객체에 영향을 주지 않도록 정리된다. 그 결과 모든 점에 의미론적으로 라벨을 지정할 수 있는 실시간 네트워크가 완성된다. 해당 네트워크는 semanticKITTI에서 훈련되었다.
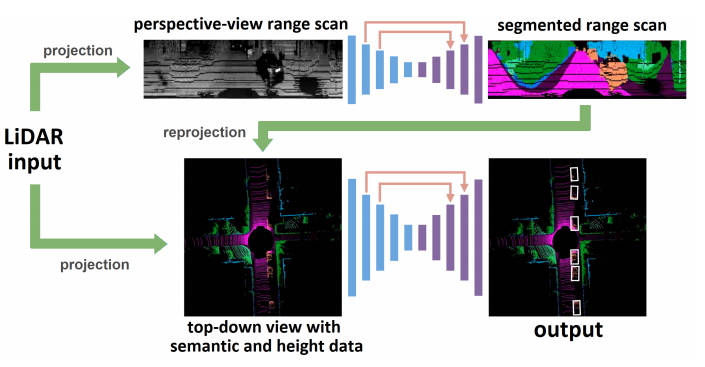
3. Method
MVLidarNet은 2 Stage로 구성되어 있다. stage-1에서는 perspective view에서 semantic segmentation이 수행되어 각종 클래스와 주행 가능 영역에 관한 정보를 얻는다. stage-2에서는 동적 물체를 탐지하기 위하여 stage-1의 결과를 BEV로 변환하여 함께 사용한다. 두 stage 모두 FPN 구조로 구성되어 있다.
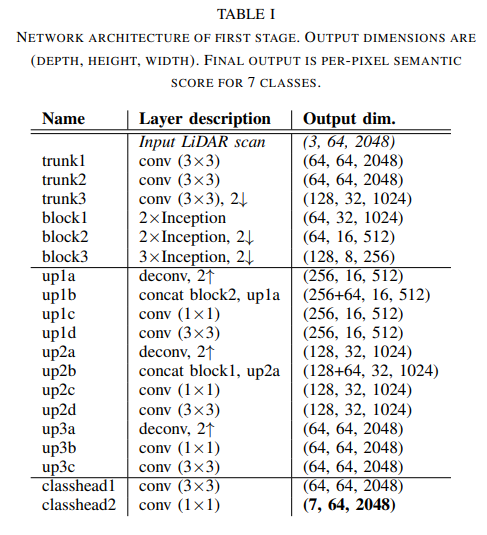
의미론적 정보를 perspective view에서 추출하는 단계이다. 각각의 LiDAR Scan의 해상도는 $n_v \times n_s$로 표현 가능하며 $n_v$는 LiDAR 채널 수와 같고, $n_s$는 채널 별 포인트 수를 의미한다. 각 포인트들은 거리 정보와 신호의 강도 정보를 동시에 가지고 있고, 이 정보를 활용하여 stage 1에서는 7개의 클래스로(Car, Truck, Pedestrian, Cyclists, Road surface, Sidewalks, unknown) segmentation을 진행한다. 이 방식을 활용하면 보행자와 자전거를 더 잘 탐지할 수 있다.
네트워크 구조는 FPN과 비슷하며, 2D Convolution/deconvolution을 활용하기 때문에 매우 빠르다. 네트워크 구조는 아래와 같다.
Stage 1의 네트워크 구조를 살펴보면 input data는 Encoder의 입력으로 들어가 몇 번의 Convolution을 거치는 구조로 구성되어 있다. 그리고 이후에 3개의 Inception 블록을 통과하여 다운 샘플링(Maxpooling 활용) 된다. 반면에 Decoder는 3개의 Deconvolution 블록을 활용하여 기존 해상도로 다시 업스케일링 하는 역할을 수행한다.
최종적으로 classification head block의 출력값을 보면 각 픽셀 당 7채널의 벡터 값을 가지는 것을 확인할 수 있다. 모든 Convolution layer에는 batch normalization과 ReLU 활성화 함수가 활용되었다. 또한 훈련에 필요한 loss function으로는 cross-entropy가 활용되었다. 이 스테이지에서는 주행 가능 영역을 직접 출력값으로 활용한다.
Semantically labeled 데이터는 BEV 형태로 재투영되고 기존에 투영된 LiDAR 데이터의 높이정보와 함께 결합된다. 이 결합된 데이터는 Stage 2의 input으로 활용된다. 이때, 단일 클래스 데이터가 아닌, 클래스일 확률 값(Class probabilities) 값을 활용하면 네트워크가 더 복잡한 추론(ex 자전거를 타고 있는 사람)을 수행할 수 있다.
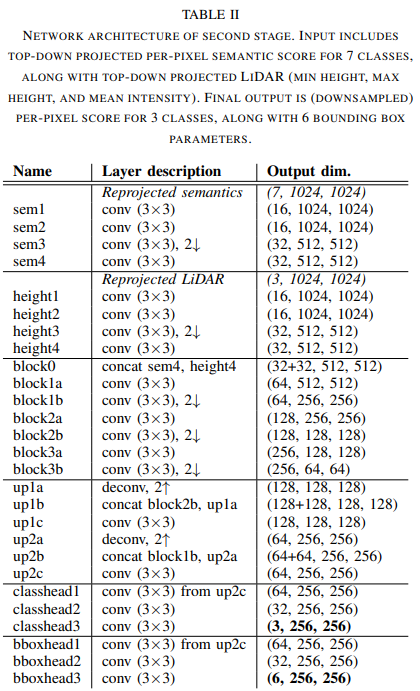
3.2 Stage 2
Stage 2 역시 classification과 bounding box regression과 encoder-decoder와 skip connection 구조를 가지고 있다. 전체 구조는 아래와 같다.
구조를 살펴보면 segmented Data와 기존 LiDAR 데이터(heights)가 동시에 input으로 들어와서 병렬로 처리되는 모습을 확인할 수 있다. 이 데이터는 encoding 과정을 거친 후 block()에서 연결(concatenation)된다. 출력 부분을 살펴보면 Classification head와 Bounding box head의 두 개의 출력을 가지는 것을 확인할 수 있는데, Class는 Car, Pedestrian, unknown의 3가지이며 Focal Loss로 훈련되며, Bbox는 $\delta_{x}, \delta_{y}, \omega_{o}, \mathcal{l}_o, sin\theta, cos\theta$로 구성되며 L1 loss로 훈련된다. $\delta_{x}, \delta_{y}$는 해당하는 물체의 무게 중심(centroid) 좌표이며, $\omega_{o} \times \mathcal{l}_o$는 물체의 dimension이다. 그리고 $\theta$는 BEV에서의 orientation을 나타낸다. 파라미터에 물체의 치수가 포함됨으로서 일반적인 승용차 이외에도 버스나 트럭 등도 포함시켜 탐지가 가능하다.
개체들의 개별 인스턴스를 파악하기 위하여 클러스터링 알고리즘이 2 Stage의 출력에 적용된다. 클러스터링 기법으론 DBSCAN 알고리즘이 사용되었다. 해당 알고리즘에선 Classification head에 의해 생성된 Class confidence 점수가 임계값을 초과하는 셀만 사용하여 회귀된 bbox의 centroid에 사용된다. 개별 bbox의 좌표나 치수, 방향은 클러스터 내부에서 normalize(평균화) 된다.
이러한 구조의 단순함은 구현하기에도 쉽고 효율적인 연산이 가능하게 한다. 이 방법은 2가지 World(Perspective view, BEV)의 장점을 모두 활용한다. 전자는 장면을 의미론적 분할을 허용하는 풍부한 모양 정보를 나타내고, 후자는 Occlusion에 자유롭다. 두 가지 모두 2D convolution 연산만을 사용하여 처리되기 때문에 연산량이 매우 적다.
4. Experimental Results
두 가지 과정을 한 번에 훈련하거나 독립적으로 훈련이 가능하다. 해당 논문에서는 KITTI와 semanticKITTI를 활용하였는데 두 가지 데이터가 합치되지 않는 특성에 의해 독립적으로 훈련시켰다. 사용된 데이터는 단일 Velodyne HDL-64E 라이다에 의해 수집되었다. Stage 1은 Class Mask만 세분화 가능하도록 훈련되었으며, 라벨링 된 LiDAR 데이터 또는 카메라에서 LiDAR로 전송된 라벨을 활용하였다. 그리고 Stage 2는 LiDAR 경계 상자 라벨에 대하여 학습된다.
Stage1의 입/출력 resolution은 64 $\times$ 2048으로 설정되며, Stage2에서는 입력은 $\omega = 1024, l = 1024$로, 출력은 256 $\times$ 256로 설정한다. (공간적인 분해능, Cell 점유율, 연산량 부하를 고려하여) 이는 $80 \times 80 m^2$의 영역을 커버하며 셀 분해능은 7.8cm/cell이다. Down-sampling 된 출력에서의 셀 분해능은 31.3cm/cell이 된다.
훈련에는 Adam optimizer를 사용하였고 초기 Learning rate=0.0001로 설정하였다. 또한 추가적으로 Stage2의 Loss에 대한 가중치로는 각각 Class = 5.0, Regression = 1.0으로 설정하여 클래스 탐지에 무게를 두었다. 훈련은 batch size=4로 40~50 epochs 반복되었고 훈련된 모델을 임베디드 GPU를 사용하여 차량에 탑재하기 위하여 TensorRT 엔진을 활용한다.
4.2 Results
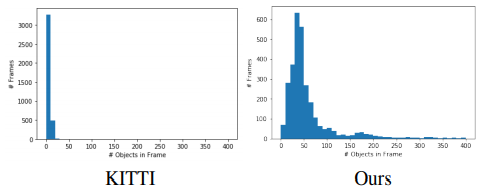
논문에서 제공한 결과 사진. 유튜브에서 연속으로 처리하는 영상을 확인할 수 있다. 해당 영상을 촬영할 때 사용한 모델을 훈련시키기 위한 Dataset은 자체적으로 구축하였다고 한다.해당 논문에서 제시한 Dataset의 histogram. 데이터 구성을 살펴보면 한 프레임 당 Object 수가 자체 구축한 Dataset에서 훨씬 많은 것을 볼 수 있다. 앞에서 언급한 도전적인 Dataset이란 말이 이를 의미한다.
위의 표는 Stage1만 적용하여 Segmentation을 진행한 결과를 Segmentation algorithm 중 하나인 RangeNet과 비교하여 정리한 표다. 표를 확인해보면 비슷한 성능을 보이면서 speed가 매우 향상된 모습을 볼 수 있다. SemanticKITTI를 활용하여 훈련하여 비교하였다.
Stage 2만 적용(BEV)하여 기타 다른 알고리즘들과도 비교하였는데 정확도는 비슷한 수준을 유지하면서 Speed 부분에서 압도적인 모습을 확인할 수 있다. KITTI를 활용하여 훈련하여 비교하였다.
위의 표를 살펴보면 BEV만 활용했을 때보다 Perspective semantics를 함게 활용하였을 때 보행자의 검출률이 눈에 띄게 상승한 모습을 확인할 수 있다. 여기에는 자신들이 구축한 Dataset을 활용하여 훈련하였다.
5. Reference
Chen, Ke, et al. "MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views." arXiv preprint arXiv:2006.05518 (2020).
RNN 계열의 알고리즘에 대해 공부하다가 Attention mechanism에 대해 접하게 되었다. 하지만 대부분의 자료를 보고는 원리를 이해하기 매우 어려웠는데, 이를 이해하기 쉽게 설명해놓은 유튜브 영상을 접하여 정리하여 포스팅한다.
1. Attention mechanism 도입의 배경
기존 RNN 방식은 연속적인 데이터를 처리하는데 특화된 알고리즘으로서 각광을 받았지만, 몇가지 문제점을 가지고 있었다.
Sequence로 입력을 모두 받은 후에 Decoding을 하는 방식이기 때문에 병렬화가 불가능하다.
고정된 크기의 Context 벡터에 모든 입력 값에 대한 정보를 압축하여 집어넣기 때문에 긴 데이터를 처리할 때 병목현상이 발생하여 정확도가 하락하게 된다.
관련 노드와의 거리가 멀어지면 Long-term dependency 특성에 의해 예측에 문제가 생긴다.
여기서 Long-term dependency 특성이란, 현재 Decoding하고 있는 영역과 그에 관련된 정보를 포함한 영역 간의 노드간 거리가 멀어질 경우, 입력 데이터의 특성이 일부 소실되었을 가능성이 커져서 그 특성을 제대로 반영하지 못하는 특성이다. 우리는 이러한 특성을 쉽게 접할 수 있는데, 주로 사용되는 분야인 번역 분야에서 굉장히 긴 문장이 입력으로 주어질 경우에 문장의 번역이 제대로 되지 않는 것이 이에 해당한다.
2. Attention mechanism이란?
포커싱에 따른 사진의 변화의 대표적인 예. Background out focusing이라고도 한다.
Attention mechanism은 영상처리 분야에서 등장한 개념이다. 사람의 눈은 자신이 보고자 하는 것에 초점을 맞춰서 봄으로서 마치 필요한 정보에 가중치를 두고 처리하는 듯한 구조를 가진다. 카메라에도 이러한 기능이 탑재되어, 원하는 부분에 포커싱이 되고 기타 영역은 블러 처리가 된 사진을 쉽게 찾을 수 있다.
이러한 구조를 RNN 계열의 알고리즘을 활용하는 것에 활용하겠다는 것이 도입의 배경이며, 만약 문장을 번역하는 데에 활용된다면 지금 번역하고 있는 단어에 따라 어떤 입력된 단어에 "주목"할 지를 가중치로서 계산하여 활용하는 것이 Attention mechanism이다. Encoder에서 나온 각각의 RNN cell의 state를 반영하며, Decoder 내부에서 가변적인 크기를 갖는 Context 벡터를 생성하여 활용하기 때문에 입력 Sequence의 길이에 영향을 적게 받는다.
3. Attention mechanism의 작동 구조
Attention mechanism을 도입한 이후부터 대부분의 RNN 계열의 시스템에는 이를 활용하는 추세다. 하지만 Attention mechanism의 작동 방법을 이해하기 쉽지 않았는데, 유튜브에 잘 정리된 자료가 있어 빌려 사용한다. 허민석 유튜브 채널의 “[딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델“을 참고하였으며,뒤에 링크를 추가하였다.
앞의 RNN을 번역 분야에서 사용하는 것을 예로 들었는데, 이번엔 Attention mechanism을 활용하여 번역하는 과정을 보이며 설명하겠다.
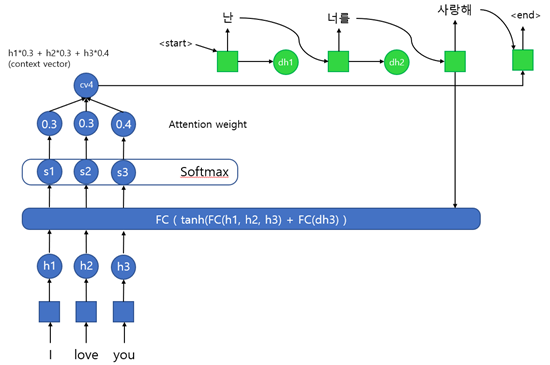
마찬가지로 입력으로 I love you라는 문장이 통째로 들어간다. 입력은 단어 단위로 히든 레이어를 통과시켜 h1, h2, h3 값을 구한다. 이 값들은 Alignment model의 입력 값으로 활용한다. 원래는 h1, h2, h3 값과 함께 이전 출력 값에 대한 정보인 dh 값이 입력으로 들어가야 하지만, 첫 번째 사이클에선 이전 출력 값이 존재하지 않기 때문에 h3 값을 입력으로 넣어준다.
Alignment model은 이 각각의 h1, h2, h3 값과 이전 출력 값과의 관계를 통해 어떤 단어에 집중하여 번역되어야 하는지에 대한 정보를 구하기 위해 작동한다. 때문에 내부를 살펴보면 Fully connected layer를 활용하여 유사도를 계산하는 것을 확인할 수 있다. 유사도를 구하기 위한 모델은 다양하게 존재한다고 한다. 계산되어 나온 이 유사도를 Attention score라고 한다.
이후 Attention score를 Softmax 함수를 활용하여 합이 1인 확률 값으로 만들어준다. 이 값을 Attention weight라고 하며 각 단어가 출력에 영향을 미치는 정도를 나타내는 가중치로 사용된다. (일부 블로그에서 이를 Attention score라고 하는 것을 봤는데, 이는 부르기 나름이기 때문에 크게 신경 쓰지 않아도 된다.)
각각의 Attention weight는 앞의 h1, h2, h3과 곱해진 후 합쳐져서 context vector를 구성한다. 즉, context vector는 각각의 사이클마다 다르게 계산되며, 크기에 제한이 없다는 것을 확인할 수 있다. 이 context vector는 이전의 출력 값(y)와 연결되어 비선형 함수를 통과하여 최종 출력 값을 계산하는데 사용된다.
첫 사이클에선 이전 출력 값이 없기 때문에 <start> 신호와 함께 연결되어 출력 값을 계산하는데 앞에서 현재의 출력과 연관이 가장 높은 단어가 “I” 였기 때문에 이를 번역한 “나”라는 단어를 배치하게 되고, start 신호로 현재 출력하는 자리가 주어 자리라는 정보를 받아 “난”으로 변환하여 출력하는 방식이라고 생각하면 이해하기 편하다.
최종 레이어의 출력은 다시 Alignment model에 입력으로 들어가며, 앞의 과정을 반복하게 된다.
이 과정을 거친 후에 작업이 완료되면 end값을 반환하고 작업을 마치게 된다. 아래의 그림은 어떤 단어끼리 관련이 있고 없는지에 대한 집중도를 plot한 그림이다. 이를 활용하면 특정 단어를 번역할 때 어떤 단어를 참고하여 번역해야 하는지에 대한 지표를 반영한 출력 값을 반환할 수 있다. 즉, Seq2Seq 네트워크의 긴 문장이 입력으로 들어왔을 때 처리하기 힘들다는 치명적인 단점을 극복하는데 활용이 가능하다.
4. Reference
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
최신 네트워크는 ImageNet과 같은 대규모 데이터셋에 의해 사전 훈련된 Backbone의 성능에 크게 의존적이다. 모델의 Fine-tuning을 활용하여 모델의 Transfer Learning을 활용한 이식에서 발생한 약간의 편향을 완화 가능하나, 근본적인 해결은 불가능하다. 또한, 다른 도메인 간의 모델 교환은 더욱 어려운 상황에 처하게 한다는 문제도 존재한다. 예를 들면 RGB image의 감지기로 사용되던 네트워크를 Depth image를 위한 모델로 활용하기 어렵다. 이 본문의 저자는 전이 학습을 사용하지 않고 처음부터 끝까지 훈련하는 방식을 제안하였다. 효율성을 극대화 하던 중, 일부 설계 원칙을 확립할 수 있었고, 계층 간의 조밀한 연결을 통해 활성화 된 Deep supervision이 우수한 검출기를 만들기 위해 중요한 역할을 한다는 것을 발견하였다. 실험은 Pascal VOC 2007, 2012와 MS COCO 데이터 셋을 활용하여 진행되었으며, SSD 기반의 네트워크를 구성하여 훈련하였다. 그 결과 Real time 기준을 만족시키면서 SSD의 성능을 능가하였다. 하지만 파라미터는 겨우 SSD의 1/2밖에 사용하지 않았다.
2. Introduction
대부분의 네트워크에서 활용하는 Transfer learning의 장단점은 아래와 같다.
* 장점
공개되어 있는 최첨단 딥-모델이 많고, 이걸 재사용하는 것은 매우 편리함.
Fine-tuning은 최종 모델을 빠르게 생성 가능하고, 라벨링 된 많은 데이터를 요구하지 않음.
* 단점
설계 가능한 여유 공간이 적음 : 사전 훈련 네트워크는 대부분 ImageNet 기반 분류기에서 가져온 것으로, 많은 파라미터가 모델에 포함되어 무겁다. 또한, 존재하는 Detector들은 직접 사전 훈련된 네트워크를 채택하여 사용하므로, 네트워크의 구조를 제어하거나 조정 혹은 수정하는데 제약이 존재한다. 또한 무거운 네트워크 구조에 의해 높은 컴퓨팅 성능이 요구된다.
학습 편향이 존재함 : 손실 함수와 분류 기준, Class의 수 등이 Backbone과 모두 다르기 때문에 최적의 값이 아닌, 다른 로컬 값으로의 수렴이 이어질 수 있다.
도메인의 불일치 : 2번의 문제는 Fine-tuning을 활용하여 다양한 클래스의 범주 분포로 인한 편향을 완화할 수 있다. 하지만 소스 도메인이 Depth image, 의료 영상 등의 아예 다른 도메인을 활용했을 때 잘못된 결과를 낼 수 있다.
이 논문은 다음 두 가지 질문으로부터 시작되었다.
첫째, 객체 감지 네트워크를 처음부터 훈련시킬 수 있을까?
둘째, 첫 번째 대답이 긍정적인 경우 높은 탐지 정확도를 유지하면서 물체 탐지를 위한 효율적인 네트워크 구조를 설계하는 원칙이 있을까?
저자는 이 질문의 답으로 처음부터 물체 감지기를 학습 할 수있는 간단하면서도 효율적인 프레임워크인 DSOD를 제안하였다. DSOD는 높은 호환성을 가졌기 때문에 서버, 데스크톱, 모바일 및 심지어 임베디드 장치와 같은 다양한 컴퓨팅 플랫폼에 대해 다양한 네트워크 구조를 조정할 수 있다는 장점을 가지고 있다.
이를 증명하기 위하여 이 논문에선 아래와 같은 작업을 수행하였다.
제한된 훈련 데이터로도 최첨단 성능으로 처음부터 물체 감지 네트워크를 훈련시킬 수있는 첫 번째 프레임워크인 DSOD를 제시하였다.
효율적인 물체 감지 네트워크를 설계하기 위해 단계별 변인 연구를 통해서 필요한 일련의 원칙을 도입하고 검증하였다.
표준 벤치 마크들을 활용하여 DSOD가 실시간 처리 속도를 보장하고 컴팩트한 모델로 높은 성능을 거둠을 증명하였다.
deep supervision은 Deeply-supervised net과 Holistically-nested edge detection에 영향을 받았다. Holistically-nested edge detection은 edge 감지를 위한 전체적인 그물망 구조를 제안하였는데, 이 구조는 Deep supervision의 각 Convolution stage에 추가 출력을 포함하는 방식이다.
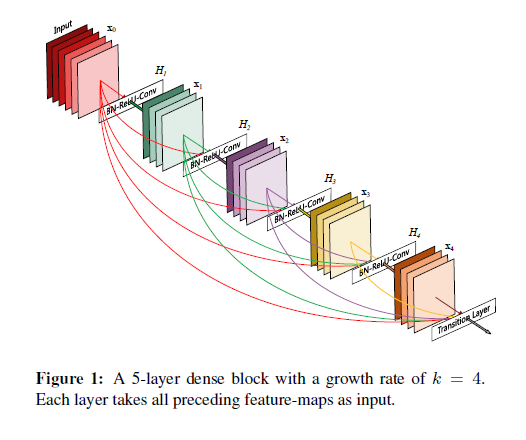
(그림1) DenseNet의 layer-wise connection
이 논문에서는다중 cut-in Loss 대신, DenseNet의 dense layer-wise connection을 사용하였다.
(그림2) 구조 비교
위의 그림은 SSD와 같은 네트워크에서 일반적으로 가지는 구조와 DSOD의 구조를 비교 한 것이다. SSD는 예측 레이어를 비대칭 모래 시계 구조로 설계하였으며, 300x300 입력 이미지의 경우 객체 예측을 위해 6가지 스케일의 피쳐 맵을 사용했다. Scale 1 피쳐 맵은 이미지의 작은 개체를 처리하기 위해 가장 큰 해상도 (38x38)를 가진 Backbone 하위 네트워크의 중간 계층에서 가져오며, 나머지 5개의 스케일은 sub-backbone 네트워크의 맨 위에 있다. 그 후, 병목 구조(피처 맵 수를 줄이기위한 1x1 conv-layer와 3x3 conv-layer)를 갖는 일반 Transition 레이어가 두 개의 연속된 피쳐 맵 스케일 사이에 사용된다. 자세한 설명은 3.1의 원칙 4에 정리하였다.
Dense 구조는 Backbone의 sub-network 뿐만 아니라 front-end 멀티 스케일 Prediction layer에서도 활용된다. 위의 그림은 front-end prediction layer의 구조 비교를 보여주며, 여기서 multi-resolution prediction-map의 융합 및 재사용은 모델 매개변수를 줄이면서 최종 정확도를 유지하거나 개선하는데 도움이 된다.
3. DSOD
3.1. DSOD Architecture
overall Framework
제안된 DSOD 방법은 SSD와 유사한 one stage 네트워크이다. DSOD의 네트워크 구조는 특징 추출을 위한 Backbone 서브 네트워크, 멀티스케일 응답 맵에 대한 예측을 위한 front-end 서브 네트워크의 두 부분으로 나눌 수 있다. Backbone 하위 네트워크는 Deeply supervise DenseNets 구조의 변형으로, stem 블록(Inception에서 제시한 앞단의 Conv 레이어), 4개의 Dense 블록, 2개의 Transition 레이어 및 풀링 없는 2개의 Transition 레이어로 구성된다. Front-ent 서브 네트워크(또는 DSOD 예측 레이어)는 정교한 Dense structure와 멀티스케일 예측 응답을 병합한다. 그림 1은 제안된 DSOD 예측 계층과 SSD에서 사용되는 멀티스케일 예측 맵의 simple structure를 보여준다. 전체 DSOD Network Architecture은 아래의 표에 자세히 설명되어 있다.
[표1] DSOD의 구조 (각 Dense 블록에 적용된 growth rate k = 48)
원칙 1: Proposal-free.
최신 CNN 기반 Object detector는 총 세가지 범주로 나눌 수 있다. 첫째, R-CNN 및 Fast R-CNN에는 Selective search와 같은 객체 영역 제안 기능이 필요하다. 둘째, Faster R-CNN 및 R-FCN은 상대적으로 적은 수의 Region proposal을 생성하기 위해 Region-Proposal-Network(RPN)를 필요로 한다. 셋째, YOLO와 SSD는 객체 위치와 경계 상자 좌표를 회귀시켜 처리하는 Single Shot 네트워크이며, 다른 범주와는 달리 Proposal이 필요 없다. 여기선 세번째 범주만이 사전 훈련되지 않은 모델로도 성공적으로 수렴할 수 있다.
그 이유는 다른 두가지 범주에는 RoI(Regions of Interest) 풀링이 존재하기 때문인데, RoI 풀링은 각 Region proposal에 대한 피쳐를 생성하여 Gradient가 Region-level에서 컨볼루션 피쳐 맵으로 원활하게 역전파되는 것을 방해한다. 또한, Proposal 방식은 사전 훈련된 네트워크 모델에서 잘 작동하는데, 이는 매개변수 초기화가 RoI 풀링 전의 계층들에 적합하지만 처음부터 훈련하는 경우에는 그렇지 않기 때문이다. 즉, 처음부터 Detection network를 훈련하려면 Proposal이 없는 프레임 워크가 필요하다. 실제로 DSOD는 SSD에서 멀티 스케일 프레임워크를 도출할 수 있다. 이는 빠른 처리 속도와 함께 높은 정확도에 도달 할 수 있기 때문이다.
원칙 2: Deep Supervision.
심층지도 학습의 효과는 GoogLeNet, DSN, DeepID3 등에서 입증되었다. 핵심 아이디어는 통합된 목적 함수를 Output Layer에서 뿐만이 아닌, 이전 Hidden Layer에 대한 직접적인 감독을 통해 제공하는 것이다. 여러 은닉 계층에서 이러한 목적 함수를 활용한 "동반하는 값"또는 "보조하는 값"은 기울기 소실 문제를 완화할 수 있다. 이 "동반 값" 목적 함수를 각 은닉 계층에 도입하기 위해선 복잡한 부차 출력 계층을 추가해야만 한다.
DSOD는 DenseNets에 소개된 dense layer-wise connection으로 심층 감독을 강화한다. 블록의 모든 선행 레이어가 현재 레이어에 연결된 경우 이 블록을 Dense 블록이라고 한다. 따라서 DenseNet의 이전 계층은 Skip Connection을 통해 목적 함수에서 추가 감독이 가능하다. 다시 말해, 네트워크 상단에는 단 하나의 손실 함수만 필요하지만 이전 계층을 포함한 모든 계층은 감독된 데이터를 공유할 수 있다.
뒤에서 서술할 풀링 레이어가 없는 Transition Layer에서 심층 감독의 이점을 확인할 수 있다. 피쳐 맵 해상도를 유지하면서 Dense 블록 수를 늘리기 위해 이 레이어(풀링 레이어가 포함되지 않은 Transition Layer)를 도입였는데, DenseNet의 원래 디자인에서 각 Transition layer에는 피쳐 맵을 다운 샘플링하는 풀링 작업이 포함되어 있다. 그 때문에 동일한 사이즈의 출력을 유지하려는 경우 Dense 블록의 수를 고정해야만 했고, 네트워크 깊이를 늘리는 유일한 방법은 DenseNet의 각 블록 내에 레이어를 추가하는 것이었다. 하지만 풀링 레이어가없는 Transition layer는 DSOD 아키텍처의 Dense 블록의 수에 대한 이러한 제약을 제거하였으며, 기존의 DenseNet에서도 사용할 수 있다.
원칙 3: Stem Block.
저자가 Inception-v3 및 v4에서 영감을 받았다는 Stem 블록을 3개의 3x3 컨볼 루션 레이어와 2x2 최대 풀링 레이어의 스택으로 정의하였다. 첫 번째 conv-layer는 stride = 2로 작동하고 다른 두 개는 stride = 1로 작동한다. 이 간단한 줄기 구조를 추가하면 실험에서 감지 성능이 반드시 향상 될 것이다. DenseNet의 원래 디자인(7x7 conv-layer, stride = 2, 3x3 max pooling, stride = 2)과 비교할 때 스템 블록은 기존 입력 이미지의 정보 손실을 줄일 수 있기 때문이라고 추측된다. 이 Stem 블록의 효과가 탐지 성능에 중요하다는 것을 뒤에서 볼 수 있다.
원칙 4: Dense Prediction Structure.
Learning Half and Reusing Half.
SSD와 같은 일반적인 구조(그림2 참조)에서 각 스케일은 인접한 이전 스케일에서 직접 전이된다. 이 논문에선 다중 스케일 정보를 융합할 수 있는 Dense structure를 제안하였다. 단순화를 위해 각 스케일의 출력이 동일한 수의 채널을 출력하도록 제한하였으며, DSOD에서 scale-1을 제외한 각 피쳐 맵의 절반은 일련의 conv-layer를 사용하여 이전 스케일에서 학습되고, 나머지 피쳐 맵은 인접한 고해상도 피쳐 맵에서 직접 다운 샘플링된다.
다운 샘플링 블록은 2x2, stride=2의 max pooling layer와 1x1, stride=1의 conv-layer로 구성한다. 풀링 계층은 해상도를 현재 크기에 맞추는 것을 연결 과정에서의 목표로 한다. 1x1 conv-layer는 채널 수를 50 %로 줄이는 데 사용된다. 풀링 레이어는 연산 비용을 절감하기 위해 1x1 conv-layer 앞에 배치된다. 이 다운 샘플링 블록은 이전의 모든 스케일에서 multi-resolution feature map을 사용하여 각 스케일을 가져 오며, 이는 본질적으로 DenseNets에 도입된 dense layer-wise connection과 동일하다. 각 스케일에서, 새로운 피쳐 맵의 절반만 학습하고 이전 피쳐 맵의 나머지 절반 을 재사용한다. 이 Dense prediction structure는 일반적인 구조보다 적은 매개변수로 더 정확한 결과를 산출 할 수 있다.
3.2. Training Settings
Caffe 프레임 워크]를 기반으로 탐지기를 구현하였음
모든 모델은 NVidia TitanX GPU에서 SGD 솔버를 사용하여 처음부터 훈련되었음
DSOD 피쳐 맵의 각 스케일은 여러 해상도에서 연결되기 때문에 L2 정규화 기술을 채택하여 모든 출력에서 피쳐의 표준을 20으로 조정하였음(SSD는이 정규화를 scale-1에만 적용하였음)
자체 Learning rate 및 미니- 배치 크기 설정을 제외한 BBOX 및 Loss Function을 포함하는 대부분의 학습 전략은 SSD를 따르며, 세부 사항은 실험 섹션에서 제공
4. Experiments
4.1. Ablation Study on PASCAL VOC 2007
[표2] 구성에 따른 DSOD의 성능 비교[표3] PASCAL VOC 2007 test set에서 진행한 실험 결과. DS/A-B-k-θ는 backbone 네트워크의 구조를 설명한다. A는 첫번째 Conv 레이어의 채널 수, B는 각 병목 레이어(1x1 conv)의 채널수, k = growth rate, θ = compression factor이다.
4.1.1. Dense Blocks의 구성
논문에선 먼저 Backbone의 하위 네트워크에 위치한 Dense 블록에서 다양한 구성의 상관관계를 조사하였다. 구성에 따른 결과는 위의 표2를 참고하면 된다.
[Transition 레이어의 압축 계수]
DenseNets의 Transition 계층에서 두 개의 압축 계수 값 (θ = 0.5, 1)을 비교한다. 결과는 표3의 2행과 3행에 나와 있다. 압축 계수 θ = 1은 Transition 레이어에서 피쳐 맵의 다운 사이징이 없음을 의미하는 반면 θ = 0.5는 피쳐 맵의 절반이 감소 함을 의미한다. 결과는 θ = 1일 때, θ = 0.5보다 2.9 % 더 높은 mAP를 달성한다는 것을 보여준다.
# 병목 레이어의 채널: 표3의 3행과 4행에서 볼 수 있듯이, 더 넓은 병목 계층(응답 맵 채널이 더 많음)이 성능을 크게 향상시키는 것으로 나타났다 (4.1 % mAP). # 첫 번째 conv-layer의 채널: 첫 번째 conv-layer에있는 많은 수의 채널이 필요하다는 것을 확인할 수 있었으며, 1.1 % mAP 향상을 가져왔다. (표의 4 행과 5 행).
[Grouth rate]
grouth rate를 나타내는 k값이 클 수록 훨씬 더 좋은 성능을 내는 것이 밝혀졌다. 4k 병목 채널에서 k를 16에서 48로 증가 시키면 표의 5행과 6행에서 4.8 % mAP 개선이 관찰되었다.
4.1.2. 디자인 원칙의 효율성 증명
[표4] PASCAL VOC 2007 test 감지 결과
[제안과정이 필요없는 프레임워크]
Faster R-CNN 및 R-FCN과 같은 제안 기반 프레임워크를 사용하여 객체 감지기를 처음부터 훈련한 프로세스는 시도한 모든 네트워크 구조(VGGNet, ResNet, DenseNet)에서 파라미터가 수렴하지 못하였다. 제안이 필요 없는 프레임워크인 SSD를 사용하여 객체 감지기를 학습 시키려고 했을 때는 학습은 성공적으로 수렴되었지만 표4에 표기된 것처럼 사전 학습 된 모델 (75.8 %)의 케이스에 비해 훨씬 더 나쁜 결과 (VGG의 경우 69.6 %)를 기록하였다. 이 실험은 Proposal-free를 활용하기 위한 설계 원칙을 검증하기 위해 시행되었다.
[Deep supervision]
논문에선 deep supervision을 통해 처음부터 물체 감지기를 훈련 시키려고 하였다. DSOD300은 77.7 % mAP를 달성하는데, 이는 VGG16 (69.6 %)을 사용하여 처음부터 훈련 된 SSD300S보다 훨씬 좋은 결과이다. 또한 SSD300 (75.8 %)의 미세 조정 결과보다 높은 결과를 보여주었다. 즉, Deep supervision의 원칙이 유효함을 입증했다고 볼 수 있다.
[풀링 레이어가 포함되지 않은 Transition] 제안된 레이어가 없는 경우(오진 3개의 Dense 블록만 존재)와 있는 경우(DSOD에서의 4개의 Dense 블록이 존재)를 비교하였다. Backbone 네트워크는 DS/32-12-16-0.5이며, 결과는 위의 표에 나와 있다. 풀링 계층이없는 Transition 블록이 있는 네트워크 구조는 1.7 %의 성능 향상을 가져와, 이 계층의 효율성을 입증하였다.
[Stem block]
표3의 6행과 9행에서 볼 수 있듯이 Stem 블록은 성능을 74.5 %에서 77.3 %로 향상시킨다. 즉 원본 이미지에서 정보 손실을 보호 할 수 있다는 추측을 입증하였다.
[Dense Prediction Structure]
속도/정확도/연산량의 세 가지 측면에서 Dense prediction 구조를 분석한다. 표4에서 볼 수 있듯이, DSOD는 추가 다운샘플링 블록의 비용으로 인해 기존 SSD보다 약간 느렸다.(17.4fps vs 20.6fps) 그러나 Dense 구조를 사용하면 mAP를 77.3 %에서 77.7 %로 개선하고 매개 변수를 18.2M에서 14.8M으로 줄일 수 있었다.(표3의 9행과 10행 참고) 또한 SSD의 예측 계층을 제안 된 Dense prediction 계층으로 교체했을 떄, 사전 학습 된 모델을 사용한 훈련에서 기존 SSD는 75.8 %에서 76.1 %로, 사용하지 않았을 때는 69.6 %에서 70.4 %로 향상 되었다. 즉, Dense prediction 레이어의 효과를 확인할 수 있었다.
[What if pre-training on ImageNet?]
pre-trained 된 ImageNet에서 하나의 light Backbone 네트워크 DS/64-12-16-1을 훈련 시켰는데, 검증 세트에서 66.8% top-1 정확도와 87.8 % top-5 정확도를 얻을 수 있었으며(VGG-16보다 약간 나쁨), “07 + 12” train val 세트에서 전체 프레임워크를 fine-tuning한 네트워크는 VOC 2007 테스트 세트에서 70.3 % mAP를 달성하였다. 이에 반해 training-from-scratch 솔루션은 70.7 %의 정확도를 달성하며 약간 더 좋은 결과를 보였다.