Motion compensation은 연속된 영상의 두 프레임의 차이가 카메라가 움직이거나 물체가 움직인 결과라는 사실을 활용한다. 이는 한 프레임을 나타내는 정보들이 다음 프레임에서 사용되는 정보와 동일함을 의미한다.
움직임 보상은 대부분의 동영상 압축 기술(MPEG-2 등)에 적용되고 있는 기술이다. 현재의 영상을 부호화하기 위하여 기존의 부호화 된 영상을 가져와서 예측을 하기 위하여 사용된다. Motion Estimation은 Motion compensation을 위해 Motion vector를 찾는 기술을 의미한다. 이와 비슷하게 비디오를 압축하는 기술은 Discrete Cosine Transform(DCT)이 있다.
아래의 내용은 Wikipedia를 참고하여 작성되었다.
2. 기능
Motion compensation은 보통 두 개의 연속된 프레임의 차이를 Difference map으로 추출하고 해당 map을 활용하여 이전 프레임과 현재 프레임 간의 shift vector를 재추출하여 Motion compensated difference map을 구한다. 두 프레임 간의 움직임 벡터만을 뽑아낸 MCD map은 이미지 자체를 활용하는 것보다 더 적은 정보를 담고 있으므로 이를 활용하면 영상의 압축이 가능하다. 따라서 보상된 프레임을 인코딩하는데 필요한 정보는 Difference map보다도 훨씬 작다.
출처: 위키피디아
3. Global Motion Compensation(GMC)
Motion 모델은 기본적으로 다음과 같은 카메라 움직임 특성들을 반영한다.
Dolly: 카메라를 앞뒤로 이동
Track: 카메라를 왼쪽 또는 오른쪽으로 이동
Boom: 카메라를 위 또는 아래로 이동
Pan: Y축을 기준으로 카메라 회전, View를 좌우로 이동
Tilt: X축을 기준으로 카메라 회전, View를 위아래로 이동
Roll: Veiw(Z) 축을 기준으로 카메라 회전
해당 보정 과정은 물체가 없는 스틸씬에 적합하며, 몇가지 장점을 가지고 있다.
몇 개의 파라미터만 가지고 비디오 시퀀스에서 주요 움직임들을 모델링이 가능하다. 파라미터들의 비트 전송률 점유율 자체는 무시가 가능하다.
프레임을 분할하지 않기 때문에 흔적이 남지 않는다.(여기서 artifacts를 흔적으로 의역하였음. artifacts가 존재할 경우 연속성 X)
프레임에서 시간축에 해당하는 직선을 따라 실제 영상은 연속적으로 움직인다. 다른 Motion compensation 체계는 시간 방향에 불연속하다.
MPEG-4 ASP(코덱이라고 보면 될듯)은 세 개의 참초 포인트가 있는 GMC를 지원하지만 보통 하나만 사용 가능하다. 단일 기준점을 사용하면 상대적으로 큰 성능 비용이 발생하여 뒤에 나올 Block motion compensation에 비해 거의 이점이 존재하지 않는다. 또한, 프레임 내에서 움직이는 물체를 표현할 수 없기 때문에 Local motion estimation도 필요하다는 단점이 존재한다.
4. Motion-compensted DCT
Block motion compensation(BMC)은 motion-compensation discrete cosine transform(MC DCT)라고도 하며, Motion compensation 테크닉으로 가장 많이 사용된다. BMC는 프레임을 이미지의 픽셀들을 블록을 나누는 방식을 활용한다.(예를 들어 MPEG에서는 16x16 픽셀 사이즈의 macro-block을 사용함) 각각의 블록은 기준 프레임에서 동일한 사이즈의 블록으로부터 각각의 블록들의 움직임을 예측한다.
인접한 블록 벡터들이 단일 이동 객체에 그려지게 되면 해당 벡터들은 중복되는 성질을 갖게된다. 이를 활용하기 위해 비트스트림(bit의 시계열)에서 현재 및 이전 Motion vector 간의 차이만 인코딩하는 것이 일반적이다. 이 과정의 결과는 패닝이 가능한 글로벌 움직임 보정과 수학적으로 동일하다. 인코딩 파이프라인 뒤에서 엔트로피 인코더는 출력 크기를 줄이기 위하여 영벡터 주변의 움직임 벡터에 대한 통계적인 분포를 활용한다.
정수가 아닌 픽셀 수만큼 블록을 이동할 수 있기 때문에 하위 픽셀 정밀도라고 한다. 중간 픽셀은 인접 픽셀을 보간하여 생성되며, 일반적으로 절반 픽셀 또는 1/4 픽셀 정밀도가 사용된다. 보간에 들어가는 연산량과 인코더에서 평가할 소스 블록 수가 많기 때문에 서브 픽셀 정밀도의 계산 비용이 훨씬 더 크다.
BMC의 주요 단점은 불연속성을 도입한다는 것이다. 블록으로 인해 블록 가장자리가 수평/수직 모서리로서 사람의 눈에도 쉽게 감지되고 푸리에 변환 계수의 양자화(quantization)로 인해 edge 현상 및 Ringing 현상이 발생한다.
BMC는 현재 프레임을 겹치지 않는 blocks로 나누고 motion compensation vector로 부터 이 블럭들이 이전 프레임의 어디서 왔는지, 어디로 이동할지를 알 수 있다.
추가로 삼각형 타일을 Motion compensation에 활용하는 방법도 제안되었다. 프레임은 삼각형으로 타일화 되고 다음 프레임은 이 삼각형들의 아핀 변환으로 생성된다. 이 과정에서 Affine 변환만이 기록/전송되며 확대/축소, 회전, 변환 등을 처리할 수 있다.
DBSCAN(Density-Based Spatial clustering of applications with noise)은 대표적인 밀도 방식의 클러스터링 기법이다. 군집 간의 거리를 이용하여 클러스터링을 하는 대표적인 알고리즘은 K-means와는 달리, 밀도를 호라용한 클러스터링은 점이 모여있는 영역을 합쳐나가는 방식이다.
각 점 데이터가 2D/3D로 흩뿌려져 있다고 가정하면 상태는 아래와 같다. 아래와 같은 데이터를 DBSCAN 알고리즘을 활용하여 클러스터링 하기 위해선 두 가지 파라미터 $\epsilon, n$을 설정해야 한다.
epsilon으로 인접하다고 판단하고 점군 데이터를 묶어줄 바운더리를 설정한다. (좌) 처리 전 점군 데이터, (우) 설정한 epsilon 데이터로 생성한 바운더리
$\epsilon$은 처리할 벡터로 부터 인접한 벡터들을 묶기 위한 거리 파라미터라고 생각하면 편하고, $n$은 해당 거리인 $\epsilon$ 안에 point가 몇 개가 있을 때 함께 묶어서 군집화 할 지를 정하는 개수 파라미터이다.
위의 두 가지 파라미터를 설정하였다면 DBSCAN Clustering을 진행할 수 있다. 해당 알고리즘을 수행할 때 벡터를 분류하는 기준은 총 4가지가 존재한다.
인접 벡터 : 현재 처리하고 있는 Point에서 $\epsilon$ 반경을 갖는 원을 그렸을 때, 그 원 내부에 존재하는 점 벡터
Core point : 자신을 포함한 인접 벡터의 수가 $n$개 이상인 점 벡터
Border point : 가장자리 벡터라고 생각하면 편하며, Core point에 연결되어 있으나 자기 자신은 Core point가 아닌 점벡터
Noise point : 다른 Core point와 연결도 되지 않고, 자기 자신도 Core point가 아닌 점벡터
또한 클러스터링을 진행할 때 적용되는 특성은 두 가지가 존재한다.
Density-reachable : Core point a와 a와 연결된 인접 벡터 b에 대하여 b는 a에 접근 가능하다. 하지만 b가 Core point가 아닌 경우엔 a에서 b로는 접근이 불가능하다.
Density-connected : 어떠한 점벡터 c와 d에 대하여 c와 d에 접근 가능한 벡터 v가 존재할 때, c와 d는 서로 연결되어 있다.
2. 알고리즘 진행 과정
위의 특성들을 모두 반영하여 클러스터링은 아래와 같이 진행된다.
여기서 Density-connected 특성까지 반영하면 최종 클러스터링 결과는 아래와 같다.
3. 결론
DBSCAN 알고리즘은 주어진 데이터들에 대해 각각의 데이터들을 세 가지(Core, Border, Noise)로 분류하는 것으로 K-Means Clustering에 비교해봐도 상당히 명확한 기준을 가지고 있는 것을 볼 수 있다. 실제로 각각의 데이터들을 분류하기 위한 거리인 $\epsilon$ 내의 데이터들의 숫자를 파악하고 또한 그 데이터들을 추가 분류함으로서 순차적으로 분류해나갈 수 있다.
K-Means와 비교하여 DBSCAN은 군집의 개수를 정의할 필요도 없으며, 군집의 형태에 영향을 받지 않는다. 또한 Noise를 따로 분류하고 영향을 받지 않기 때문에 더욱 명확한 분류가 가능하다.
하지만 다양한 밀도를 가지는 데이터의 분류에 적합하지 않고, 고차원 데이터에 대해서 적절한 $\epsilon$ 값을 찾기 어렵다는 단점도 존재한다.
적합한 $\epsilon$ 값은 k-distance graph를 활용하여 구할 수 있다. 좋은 $\epsilon$ 값은 묶인 데이터들끼리 강력한 기준에 부합되게 분류되는 값이며, 극단적으로 크면 한 군집만이 만들어지고 작으면 대부분의 데이터가 클러스터링 되지 않을 것이다. 아래의 사진은 출처의 블로그에서 다양한 밀도의 데이터에 대해 DBSCAN Clustering 작업을 수행한 결과이다. 밀도가 높은 곳에 집중하기 때문에 밀도가 낮은 곳을 하나의 클러스터로 인식하지 못하고 노이즈로 처리한 모습을 볼 수 있다.
RNN 계열의 알고리즘에 대해 공부하다가 Attention mechanism에 대해 접하게 되었다. 하지만 대부분의 자료를 보고는 원리를 이해하기 매우 어려웠는데, 이를 이해하기 쉽게 설명해놓은 유튜브 영상을 접하여 정리하여 포스팅한다.
1. Attention mechanism 도입의 배경
기존 RNN 방식은 연속적인 데이터를 처리하는데 특화된 알고리즘으로서 각광을 받았지만, 몇가지 문제점을 가지고 있었다.
Sequence로 입력을 모두 받은 후에 Decoding을 하는 방식이기 때문에 병렬화가 불가능하다.
고정된 크기의 Context 벡터에 모든 입력 값에 대한 정보를 압축하여 집어넣기 때문에 긴 데이터를 처리할 때 병목현상이 발생하여 정확도가 하락하게 된다.
관련 노드와의 거리가 멀어지면 Long-term dependency 특성에 의해 예측에 문제가 생긴다.
여기서 Long-term dependency 특성이란, 현재 Decoding하고 있는 영역과 그에 관련된 정보를 포함한 영역 간의 노드간 거리가 멀어질 경우, 입력 데이터의 특성이 일부 소실되었을 가능성이 커져서 그 특성을 제대로 반영하지 못하는 특성이다. 우리는 이러한 특성을 쉽게 접할 수 있는데, 주로 사용되는 분야인 번역 분야에서 굉장히 긴 문장이 입력으로 주어질 경우에 문장의 번역이 제대로 되지 않는 것이 이에 해당한다.
2. Attention mechanism이란?
포커싱에 따른 사진의 변화의 대표적인 예. Background out focusing이라고도 한다.
Attention mechanism은 영상처리 분야에서 등장한 개념이다. 사람의 눈은 자신이 보고자 하는 것에 초점을 맞춰서 봄으로서 마치 필요한 정보에 가중치를 두고 처리하는 듯한 구조를 가진다. 카메라에도 이러한 기능이 탑재되어, 원하는 부분에 포커싱이 되고 기타 영역은 블러 처리가 된 사진을 쉽게 찾을 수 있다.
이러한 구조를 RNN 계열의 알고리즘을 활용하는 것에 활용하겠다는 것이 도입의 배경이며, 만약 문장을 번역하는 데에 활용된다면 지금 번역하고 있는 단어에 따라 어떤 입력된 단어에 "주목"할 지를 가중치로서 계산하여 활용하는 것이 Attention mechanism이다. Encoder에서 나온 각각의 RNN cell의 state를 반영하며, Decoder 내부에서 가변적인 크기를 갖는 Context 벡터를 생성하여 활용하기 때문에 입력 Sequence의 길이에 영향을 적게 받는다.
3. Attention mechanism의 작동 구조
Attention mechanism을 도입한 이후부터 대부분의 RNN 계열의 시스템에는 이를 활용하는 추세다. 하지만 Attention mechanism의 작동 방법을 이해하기 쉽지 않았는데, 유튜브에 잘 정리된 자료가 있어 빌려 사용한다. 허민석 유튜브 채널의 “[딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델“을 참고하였으며,뒤에 링크를 추가하였다.
앞의 RNN을 번역 분야에서 사용하는 것을 예로 들었는데, 이번엔 Attention mechanism을 활용하여 번역하는 과정을 보이며 설명하겠다.
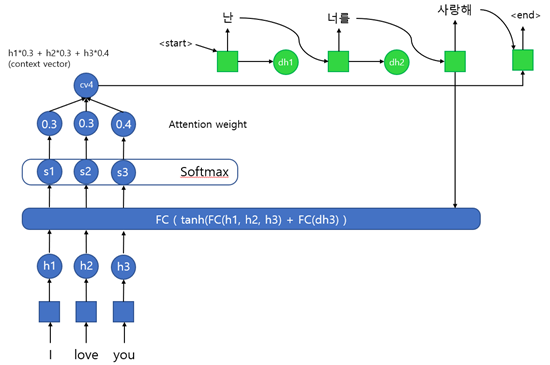
마찬가지로 입력으로 I love you라는 문장이 통째로 들어간다. 입력은 단어 단위로 히든 레이어를 통과시켜 h1, h2, h3 값을 구한다. 이 값들은 Alignment model의 입력 값으로 활용한다. 원래는 h1, h2, h3 값과 함께 이전 출력 값에 대한 정보인 dh 값이 입력으로 들어가야 하지만, 첫 번째 사이클에선 이전 출력 값이 존재하지 않기 때문에 h3 값을 입력으로 넣어준다.
Alignment model은 이 각각의 h1, h2, h3 값과 이전 출력 값과의 관계를 통해 어떤 단어에 집중하여 번역되어야 하는지에 대한 정보를 구하기 위해 작동한다. 때문에 내부를 살펴보면 Fully connected layer를 활용하여 유사도를 계산하는 것을 확인할 수 있다. 유사도를 구하기 위한 모델은 다양하게 존재한다고 한다. 계산되어 나온 이 유사도를 Attention score라고 한다.
이후 Attention score를 Softmax 함수를 활용하여 합이 1인 확률 값으로 만들어준다. 이 값을 Attention weight라고 하며 각 단어가 출력에 영향을 미치는 정도를 나타내는 가중치로 사용된다. (일부 블로그에서 이를 Attention score라고 하는 것을 봤는데, 이는 부르기 나름이기 때문에 크게 신경 쓰지 않아도 된다.)
각각의 Attention weight는 앞의 h1, h2, h3과 곱해진 후 합쳐져서 context vector를 구성한다. 즉, context vector는 각각의 사이클마다 다르게 계산되며, 크기에 제한이 없다는 것을 확인할 수 있다. 이 context vector는 이전의 출력 값(y)와 연결되어 비선형 함수를 통과하여 최종 출력 값을 계산하는데 사용된다.
첫 사이클에선 이전 출력 값이 없기 때문에 <start> 신호와 함께 연결되어 출력 값을 계산하는데 앞에서 현재의 출력과 연관이 가장 높은 단어가 “I” 였기 때문에 이를 번역한 “나”라는 단어를 배치하게 되고, start 신호로 현재 출력하는 자리가 주어 자리라는 정보를 받아 “난”으로 변환하여 출력하는 방식이라고 생각하면 이해하기 편하다.
최종 레이어의 출력은 다시 Alignment model에 입력으로 들어가며, 앞의 과정을 반복하게 된다.
이 과정을 거친 후에 작업이 완료되면 end값을 반환하고 작업을 마치게 된다. 아래의 그림은 어떤 단어끼리 관련이 있고 없는지에 대한 집중도를 plot한 그림이다. 이를 활용하면 특정 단어를 번역할 때 어떤 단어를 참고하여 번역해야 하는지에 대한 지표를 반영한 출력 값을 반환할 수 있다. 즉, Seq2Seq 네트워크의 긴 문장이 입력으로 들어왔을 때 처리하기 힘들다는 치명적인 단점을 극복하는데 활용이 가능하다.
4. Reference
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.