자율주행에는 주행 중에 마주칠 수 있는 다양한 물체들의 종류를 판별하고 그 물체까지의 거리를 파악하여 차량을 동역학적으로 제어하는 능력이 필요하다. 보통 자율주행의 3요소라고 함은 Perception, Control, Localization & Mapping를 의미하는데 이 기능들이 모두 정확하게 기능해야만 완벽한 자율주행이 가능하다. 딥러닝은 모든 분야에 적용이 가능하지만 보통 이미지나 데이터로부터 라벨을 예측하는 분야는 Perception에 해당한다.
해당 논문은 차량에 탑재되는 LiDAR를 활용하여 다중 클래스 감지와 주행 가능 영역을 감지가능한 2-Stage DNN 알고리즘을 소개한다. 기존 알고리즘들은 Voxel 구조가 3D이기 때문에 3D Convolution을 활용해왔고, 이 때문에 많은 파라미터를 학습시키고 활용해야 해서 높은 FPS를 얻기 힘들다고 알고 있었는데, 실시간 처리를 강조한 논문이란 점이 인상적이었다. 2020년 IROS 컨퍼런스에서 발표된 논문이고, 현재까지 인용수는 3회이다.
1. Introduction
전통적으로 다양한 물체를 감지하고 해당 물체까지의 거리를 취하기 위해서 RGB 이미지와 LiDAR 데이터를 동시에 활용하는 방법을 활용해왔다. RGB 이미지는 물체의 Class를 판별하는 것에 강점을 가지고 있고, LiDAR 데이터는 물체까지의 거리를 판별하는 것에 강점을 가지고 있기 때문이다. 하지만 RGB 이미지는 카메라를 활용하여 3D World를 2D image에 투영하는 방식으로 제작되어 기하학적으로 부정확한 문제가 발생한다. LiDAR는 이러한 문제를 해결 할 수 있지만 3D 포인트 클라우드를 처리하는 데에 문제를 가지고 있다.
이를 해결하기 위하여 3D 포인트 클라우드를 3D Voxel grids로 처리하곤 하지만 연산량이 너무 높고 처리 과정에서 양자화 오류가 발생한다. 또다른 방법은 BEV(Bird Eye's View)에 투영하여 처리하는데 이 방식은 보행자의 크기가 너무 작아져서 정보의 손실이 발생한다.
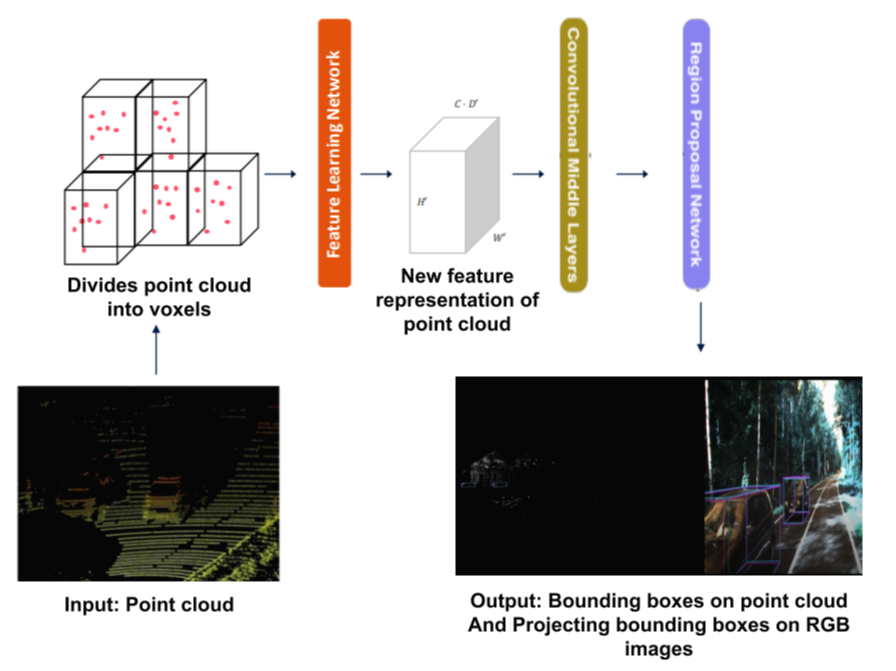
이 논문에서 제시한 내용을 정리하면 아래와 같다.
- 두 개의 서로 다른 View를 활용하여 LiDAR 입력을 처리하는 단일 네트워크로 차량과 보행자를 감지할 수 있고 주행 가능 영역을 감지할 수 있는 Multi-View Multi-Class 시스템을 제안
- 단순한 구조를 활용하여 해당 시스템은 임베디드 GPU에서 150fps로 매우 빠른 속도로 동작한다.
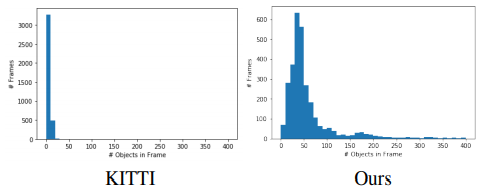
- 결과 값은 프레임 당 100대 이상의 자동차와 사람들이 표시된 매우 도전적인(extremely challenging) 데이터 환경에서 시연되므로 최첨단 자율주행 LiDAR perception 분야에 진보를 가져올 수 있다.
2. Related Works
[1] PIXOR는 2D Convolution을 활용하여 Multi-channel BEV tensor로 투영된 LiDAR Point Clouds에서 객체를 감지한다. 네트워크는 Confidence map을 연산하고 각 출력 픽셀에 대한 Bounding box의 위치, 크기 및 방향을 Regression한다. Bounding box는 Clustering 과정으로 추출된다. 이러한 방식은 빠르지만 보행자와 같은 물체는 BEV에서 다른 물체와 구별이 힘들기 때문에 오검출 문제가 발생한다.
[2] Fast and Furious는 동시 감지, Object tracking, 동작 예측을 다룬다. 접근 방식은 PIXOR과 비슷하지만 일부 버전은 Voxel화 된 Point clouds(4D tensor)에 적용된 3D Convolution을 사용하기 때문에 느리다. 또한 결과는 자체적인 데이터셋에 대해서만 제시되었다.
[3] VoxelNet은 밀도가 높은 복셀을 만들기 위해 무작위로 서브샘플링된 3D LiDAR Point clouds를 Voxelize한다. RPN이 3D 객체 감지를 위해 사용되고 복셀은 3D 텐서로 변환된다. 이로 인해 실행 시간은 느려지고, 복셀화 단계에서 정보 손실이 발생한다.
# Random Sub-sampling이란?
LiDAR Data를 전처리하기 위해서 Voxel grids로 쪼개기 전에 랜덤으로 일부 Points만을 뽑아내는 과정을 Random Sub-Sampling이라고 한다.
샘플링 된 데이터는 정육면체 꼴을 띄는 Voxel에 의해 묶이게 되며 Voxel의 크기가 클 수록 점 군의 개수가 줄어든다. 해외 블로그 중 정리가 잘 된 자료가 있어서 가져와봤다.


[4] SECOND는 point clouds를 Voxel feature 및 좌표로 변환하여 sparse Convolution을 적용한 후 RPN을 적용한다. 정보는 3D 데이터를 다운 샘플링하기 전에 Point Clouds에서 수직으로(vertically 추출된다.) 런타임은 개선되었지만 Voxelize 단계에서 정보 손실은 여전히 발생한다.
[5] MV3D는 Point clouds를 높이 맵과 intensity를 나타내는 여러 채널이 존재하는 다중 채널 BEV로 변환한다. 정확도를 높이기 위해 LiDAR 및 RGB 카메라 데이터를 모두 활용하며 Perspective view를 이미지에 결합하고 Region proposal이 3D 감지에 사용된다.
[6] AVOD 역시 LiDAR와 RGB를 모두 사용하며, FPN 및 RPN에 기반한 새로운 Feature 추출기를 활용하여 물체를 감지한다.
[7] PointNet은 3D Point clouds에서 직접 작동하는 객체 분류 및 포인트 별로 Semantic segmentation을 수행한다.
[8] PointPillars는 LiDAR Point clouds만 사용하고, PointNet을 활용하여 Point clouds를 Column로 구성함으로써 높은 성능과 속도를 동시에 달성한다. 네트워크는 포인트를 인코딩하고 단순화 된 PointNet을 실행하고 SSD(Single Shot multi object Detector)를 사용하여 물체를 감지한다.
[9] STD는 Point clouds의 semantic segmentation을 위한 PointNet++와 분류/회귀 예측을 위한 proposal generation network의 2 Stage를 활용한다.
[10] Lidar DNN은 이 논문과 같은 방식으로 Point clouds의 Perspective view 및 BEV를 사용한다. Bounding box는 supervision target으로 사용되며 네트워크는 두 병렬 구조로 2D Convolution을 활용하여 각 View에서 특징을 추출하는 방법을 학습한다. 결과는 단일 클래스 객체 감지를 보인다. (MVLidarNet은 다중 클래스 객체 감지를 수행하고 더 빠른 감지를 보임)
[11] RangeNet++는 2D semantic segmentation 네트워크가 적용되는 ego-centric 범위의 이미지에 point clouds를 구형으로 투영한다. k-nearest neighbor(kNN) 후처리가 투영되지 않은 분할된 point clouds에 적용되어 인접 객체에 영향을 주지 않도록 정리된다. 그 결과 모든 점에 의미론적으로 라벨을 지정할 수 있는 실시간 네트워크가 완성된다. 해당 네트워크는 semanticKITTI에서 훈련되었다.
3. Method
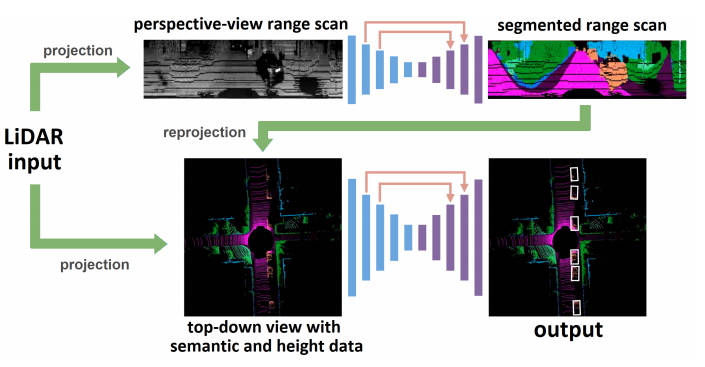
LiDAR 데이터는 360˚를 커버하며 각각은 perspective(구(球)형의) view와 top-down(직교형)로 투영된다.
3.1 Stage 1
의미론적 정보를 perspective view에서 추출하는 단계이다. 각각의 LiDAR Scan의 해상도는 $n_v \times n_s$로 표현 가능하며 $n_v$는 LiDAR 채널 수와 같고, $n_s$는 채널 별 포인트 수를 의미한다. 각 포인트들은 거리 정보와 신호의 강도 정보를 동시에 가지고 있고, 이 정보를 활용하여 stage 1에서는 7개의 클래스로(Car, Truck, Pedestrian, Cyclists, Road surface, Sidewalks, unknown) segmentation을 진행한다. 이 방식을 활용하면 보행자와 자전거를 더 잘 탐지할 수 있다.
네트워크 구조는 FPN과 비슷하며, 2D Convolution/deconvolution을 활용하기 때문에 매우 빠르다. 네트워크 구조는 아래와 같다.
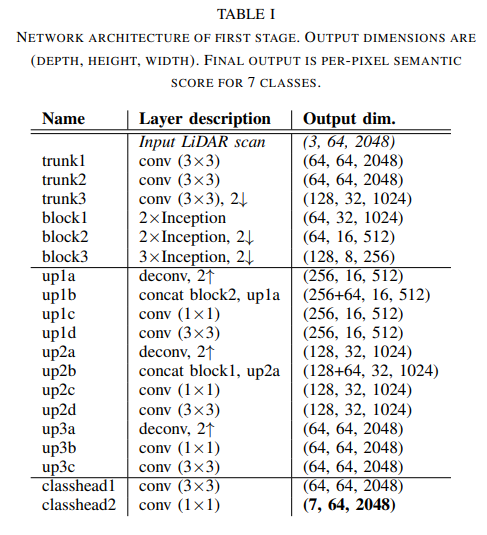
Stage 1의 네트워크 구조를 살펴보면 input data는 Encoder의 입력으로 들어가 몇 번의 Convolution을 거치는 구조로 구성되어 있다. 그리고 이후에 3개의 Inception 블록을 통과하여 다운 샘플링(Maxpooling 활용) 된다. 반면에 Decoder는 3개의 Deconvolution 블록을 활용하여 기존 해상도로 다시 업스케일링 하는 역할을 수행한다.
최종적으로 classification head block의 출력값을 보면 각 픽셀 당 7채널의 벡터 값을 가지는 것을 확인할 수 있다. 모든 Convolution layer에는 batch normalization과 ReLU 활성화 함수가 활용되었다. 또한 훈련에 필요한 loss function으로는 cross-entropy가 활용되었다. 이 스테이지에서는 주행 가능 영역을 직접 출력값으로 활용한다.
Semantically labeled 데이터는 BEV 형태로 재투영되고 기존에 투영된 LiDAR 데이터의 높이정보와 함께 결합된다. 이 결합된 데이터는 Stage 2의 input으로 활용된다. 이때, 단일 클래스 데이터가 아닌, 클래스일 확률 값(Class probabilities) 값을 활용하면 네트워크가 더 복잡한 추론(ex 자전거를 타고 있는 사람)을 수행할 수 있다.
3.2 Stage 2
Stage 2 역시 classification과 bounding box regression과 encoder-decoder와 skip connection 구조를 가지고 있다. 전체 구조는 아래와 같다.
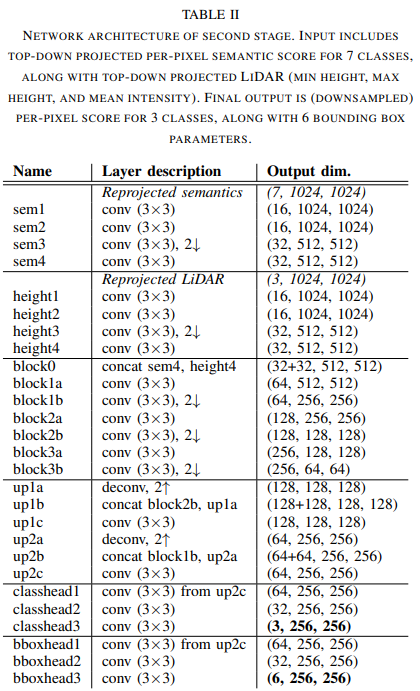
구조를 살펴보면 segmented Data와 기존 LiDAR 데이터(heights)가 동시에 input으로 들어와서 병렬로 처리되는 모습을 확인할 수 있다. 이 데이터는 encoding 과정을 거친 후 block()에서 연결(concatenation)된다. 출력 부분을 살펴보면 Classification head와 Bounding box head의 두 개의 출력을 가지는 것을 확인할 수 있는데, Class는 Car, Pedestrian, unknown의 3가지이며 Focal Loss로 훈련되며, Bbox는 $\delta_{x}, \delta_{y}, \omega_{o}, \mathcal{l}_o, sin\theta, cos\theta$로 구성되며 L1 loss로 훈련된다. $\delta_{x}, \delta_{y}$는 해당하는 물체의 무게 중심(centroid) 좌표이며, $\omega_{o} \times \mathcal{l}_o$는 물체의 dimension이다. 그리고 $\theta$는 BEV에서의 orientation을 나타낸다. 파라미터에 물체의 치수가 포함됨으로서 일반적인 승용차 이외에도 버스나 트럭 등도 포함시켜 탐지가 가능하다.
개체들의 개별 인스턴스를 파악하기 위하여 클러스터링 알고리즘이 2 Stage의 출력에 적용된다. 클러스터링 기법으론 DBSCAN 알고리즘이 사용되었다. 해당 알고리즘에선 Classification head에 의해 생성된 Class confidence 점수가 임계값을 초과하는 셀만 사용하여 회귀된 bbox의 centroid에 사용된다. 개별 bbox의 좌표나 치수, 방향은 클러스터 내부에서 normalize(평균화) 된다.
이러한 구조의 단순함은 구현하기에도 쉽고 효율적인 연산이 가능하게 한다. 이 방법은 2가지 World(Perspective view, BEV)의 장점을 모두 활용한다. 전자는 장면을 의미론적 분할을 허용하는 풍부한 모양 정보를 나타내고, 후자는 Occlusion에 자유롭다. 두 가지 모두 2D convolution 연산만을 사용하여 처리되기 때문에 연산량이 매우 적다.
4. Experimental Results
두 가지 과정을 한 번에 훈련하거나 독립적으로 훈련이 가능하다. 해당 논문에서는 KITTI와 semanticKITTI를 활용하였는데 두 가지 데이터가 합치되지 않는 특성에 의해 독립적으로 훈련시켰다. 사용된 데이터는 단일 Velodyne HDL-64E 라이다에 의해 수집되었다. Stage 1은 Class Mask만 세분화 가능하도록 훈련되었으며, 라벨링 된 LiDAR 데이터 또는 카메라에서 LiDAR로 전송된 라벨을 활용하였다. 그리고 Stage 2는 LiDAR 경계 상자 라벨에 대하여 학습된다.
4.1 Setting
입력 LiDAR 데이터는 훈련 및 추론을 위해 모션 보상(Motion Compensate)된다.
Stage1의 입/출력 resolution은 64 $\times$ 2048으로 설정되며, Stage2에서는 입력은 $\omega = 1024, l = 1024$로, 출력은 256 $\times$ 256로 설정한다. (공간적인 분해능, Cell 점유율, 연산량 부하를 고려하여) 이는 $80 \times 80 m^2$의 영역을 커버하며 셀 분해능은 7.8cm/cell이다. Down-sampling 된 출력에서의 셀 분해능은 31.3cm/cell이 된다.
훈련에는 Adam optimizer를 사용하였고 초기 Learning rate=0.0001로 설정하였다. 또한 추가적으로 Stage2의 Loss에 대한 가중치로는 각각 Class = 5.0, Regression = 1.0으로 설정하여 클래스 탐지에 무게를 두었다. 훈련은 batch size=4로 40~50 epochs 반복되었고 훈련된 모델을 임베디드 GPU를 사용하여 차량에 탑재하기 위하여 TensorRT 엔진을 활용한다.
4.2 Results

동영상 링크 : https://www.youtube.com/watch?v=2ck5_sToayc

위의 표는 Stage1만 적용하여 Segmentation을 진행한 결과를 Segmentation algorithm 중 하나인 RangeNet과 비교하여 정리한 표다. 표를 확인해보면 비슷한 성능을 보이면서 speed가 매우 향상된 모습을 볼 수 있다. SemanticKITTI를 활용하여 훈련하여 비교하였다.
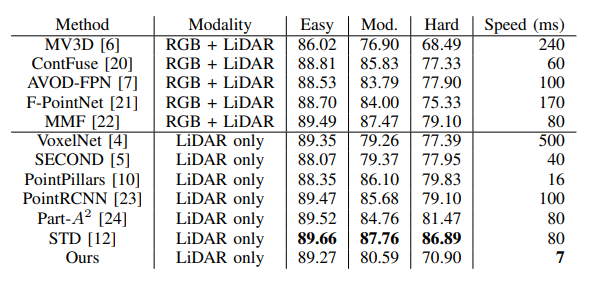
Stage 2만 적용(BEV)하여 기타 다른 알고리즘들과도 비교하였는데 정확도는 비슷한 수준을 유지하면서 Speed 부분에서 압도적인 모습을 확인할 수 있다. KITTI를 활용하여 훈련하여 비교하였다.

위의 표를 살펴보면 BEV만 활용했을 때보다 Perspective semantics를 함게 활용하였을 때 보행자의 검출률이 눈에 띄게 상승한 모습을 확인할 수 있다. 여기에는 자신들이 구축한 Dataset을 활용하여 훈련하였다.
5. Reference
Chen, Ke, et al. "MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views." arXiv preprint arXiv:2006.05518 (2020).