1. Abstract
최신 네트워크는 ImageNet과 같은 대규모 데이터셋에 의해 사전 훈련된 Backbone의 성능에 크게 의존적이다. 모델의 Fine-tuning을 활용하여 모델의 Transfer Learning을 활용한 이식에서 발생한 약간의 편향을 완화 가능하나, 근본적인 해결은 불가능하다.
또한, 다른 도메인 간의 모델 교환은 더욱 어려운 상황에 처하게 한다는 문제도 존재한다. 예를 들면 RGB image의 감지기로 사용되던 네트워크를 Depth image를 위한 모델로 활용하기 어렵다.
이 본문의 저자는 전이 학습을 사용하지 않고 처음부터 끝까지 훈련하는 방식을 제안하였다. 효율성을 극대화 하던 중, 일부 설계 원칙을 확립할 수 있었고, 계층 간의 조밀한 연결을 통해 활성화 된 Deep supervision이 우수한 검출기를 만들기 위해 중요한 역할을 한다는 것을 발견하였다.
실험은 Pascal VOC 2007, 2012와 MS COCO 데이터 셋을 활용하여 진행되었으며, SSD 기반의 네트워크를 구성하여 훈련하였다. 그 결과 Real time 기준을 만족시키면서 SSD의 성능을 능가하였다. 하지만 파라미터는 겨우 SSD의 1/2밖에 사용하지 않았다.
2. Introduction
대부분의 네트워크에서 활용하는 Transfer learning의 장단점은 아래와 같다.
* 장점
- 공개되어 있는 최첨단 딥-모델이 많고, 이걸 재사용하는 것은 매우 편리함.
- Fine-tuning은 최종 모델을 빠르게 생성 가능하고, 라벨링 된 많은 데이터를 요구하지 않음.
* 단점
- 설계 가능한 여유 공간이 적음 : 사전 훈련 네트워크는 대부분 ImageNet 기반 분류기에서 가져온 것으로, 많은 파라미터가 모델에 포함되어 무겁다. 또한, 존재하는 Detector들은 직접 사전 훈련된 네트워크를 채택하여 사용하므로, 네트워크의 구조를 제어하거나 조정 혹은 수정하는데 제약이 존재한다. 또한 무거운 네트워크 구조에 의해 높은 컴퓨팅 성능이 요구된다.
- 학습 편향이 존재함 : 손실 함수와 분류 기준, Class의 수 등이 Backbone과 모두 다르기 때문에 최적의 값이 아닌, 다른 로컬 값으로의 수렴이 이어질 수 있다.
- 도메인의 불일치 : 2번의 문제는 Fine-tuning을 활용하여 다양한 클래스의 범주 분포로 인한 편향을 완화할 수 있다. 하지만 소스 도메인이 Depth image, 의료 영상 등의 아예 다른 도메인을 활용했을 때 잘못된 결과를 낼 수 있다.
이 논문은 다음 두 가지 질문으로부터 시작되었다.
첫째, 객체 감지 네트워크를 처음부터 훈련시킬 수 있을까?
둘째, 첫 번째 대답이 긍정적인 경우 높은 탐지 정확도를 유지하면서 물체 탐지를 위한 효율적인 네트워크 구조를 설계하는 원칙이 있을까?
저자는 이 질문의 답으로 처음부터 물체 감지기를 학습 할 수있는 간단하면서도 효율적인 프레임워크인 DSOD를 제안하였다. DSOD는 높은 호환성을 가졌기 때문에 서버, 데스크톱, 모바일 및 심지어 임베디드 장치와 같은 다양한 컴퓨팅 플랫폼에 대해 다양한 네트워크 구조를 조정할 수 있다는 장점을 가지고 있다.
이를 증명하기 위하여 이 논문에선 아래와 같은 작업을 수행하였다.
- 제한된 훈련 데이터로도 최첨단 성능으로 처음부터 물체 감지 네트워크를 훈련시킬 수있는 첫 번째 프레임워크인 DSOD를 제시하였다.
- 효율적인 물체 감지 네트워크를 설계하기 위해 단계별 변인 연구를 통해서 필요한 일련의 원칙을 도입하고 검증하였다.
- 표준 벤치 마크들을 활용하여 DSOD가 실시간 처리 속도를 보장하고 컴팩트한 모델로 높은 성능을 거둠을 증명하였다.
deep supervision은 Deeply-supervised net과 Holistically-nested edge detection에 영향을 받았다. Holistically-nested edge detection은 edge 감지를 위한 전체적인 그물망 구조를 제안하였는데, 이 구조는 Deep supervision의 각 Convolution stage에 추가 출력을 포함하는 방식이다.

이 논문에서는 다중 cut-in Loss 대신, DenseNet의 dense layer-wise connection을 사용하였다.
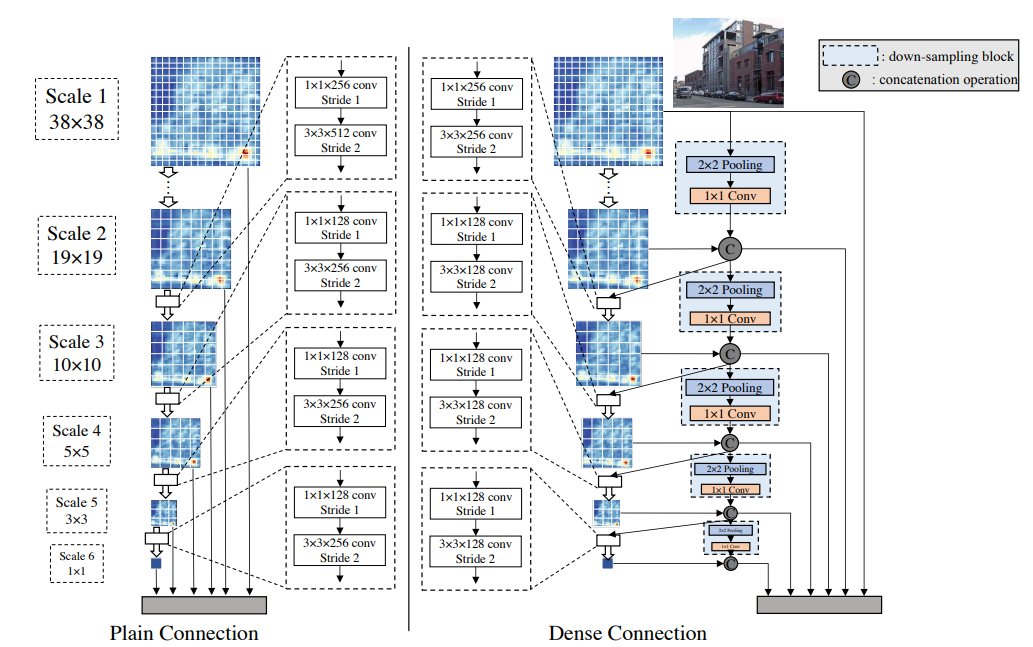
위의 그림은 SSD와 같은 네트워크에서 일반적으로 가지는 구조와 DSOD의 구조를 비교 한 것이다. SSD는 예측 레이어를 비대칭 모래 시계 구조로 설계하였으며, 300x300 입력 이미지의 경우 객체 예측을 위해 6가지 스케일의 피쳐 맵을 사용했다. Scale 1 피쳐 맵은 이미지의 작은 개체를 처리하기 위해 가장 큰 해상도 (38x38)를 가진 Backbone 하위 네트워크의 중간 계층에서 가져오며, 나머지 5개의 스케일은 sub-backbone 네트워크의 맨 위에 있다. 그 후, 병목 구조(피처 맵 수를 줄이기위한 1x1 conv-layer와 3x3 conv-layer)를 갖는 일반 Transition 레이어가 두 개의 연속된 피쳐 맵 스케일 사이에 사용된다. 자세한 설명은 3.1의 원칙 4에 정리하였다.
Dense 구조는 Backbone의 sub-network 뿐만 아니라 front-end 멀티 스케일 Prediction layer에서도 활용된다. 위의 그림은 front-end prediction layer의 구조 비교를 보여주며, 여기서 multi-resolution prediction-map의 융합 및 재사용은 모델 매개변수를 줄이면서 최종 정확도를 유지하거나 개선하는데 도움이 된다.
3. DSOD
3.1. DSOD Architecture
overall Framework
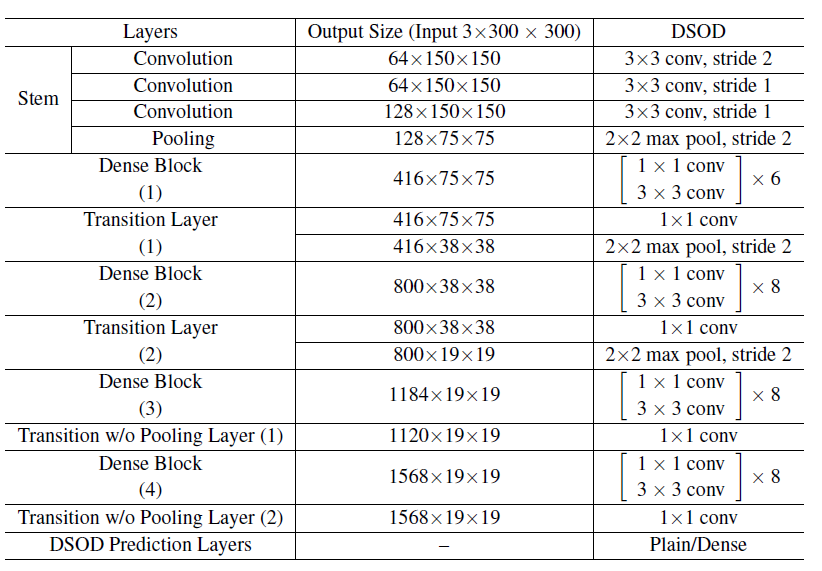
제안된 DSOD 방법은 SSD와 유사한 one stage 네트워크이다. DSOD의 네트워크 구조는 특징 추출을 위한 Backbone 서브 네트워크, 멀티스케일 응답 맵에 대한 예측을 위한 front-end 서브 네트워크의 두 부분으로 나눌 수 있다. Backbone 하위 네트워크는 Deeply supervise DenseNets 구조의 변형으로, stem 블록(Inception에서 제시한 앞단의 Conv 레이어), 4개의 Dense 블록, 2개의 Transition 레이어 및 풀링 없는 2개의 Transition 레이어로 구성된다. Front-ent 서브 네트워크(또는 DSOD 예측 레이어)는 정교한 Dense structure와 멀티스케일 예측 응답을 병합한다. 그림 1은 제안된 DSOD 예측 계층과 SSD에서 사용되는 멀티스케일 예측 맵의 simple structure를 보여준다. 전체 DSOD Network Architecture은 아래의 표에 자세히 설명되어 있다.
원칙 1: Proposal-free.
최신 CNN 기반 Object detector는 총 세가지 범주로 나눌 수 있다. 첫째, R-CNN 및 Fast R-CNN에는 Selective search와 같은 객체 영역 제안 기능이 필요하다. 둘째, Faster R-CNN 및 R-FCN은 상대적으로 적은 수의 Region proposal을 생성하기 위해 Region-Proposal-Network(RPN)를 필요로 한다. 셋째, YOLO와 SSD는 객체 위치와 경계 상자 좌표를 회귀시켜 처리하는 Single Shot 네트워크이며, 다른 범주와는 달리 Proposal이 필요 없다. 여기선 세번째 범주만이 사전 훈련되지 않은 모델로도 성공적으로 수렴할 수 있다.
그 이유는 다른 두가지 범주에는 RoI(Regions of Interest) 풀링이 존재하기 때문인데, RoI 풀링은 각 Region proposal에 대한 피쳐를 생성하여 Gradient가 Region-level에서 컨볼루션 피쳐 맵으로 원활하게 역전파되는 것을 방해한다. 또한, Proposal 방식은 사전 훈련된 네트워크 모델에서 잘 작동하는데, 이는 매개변수 초기화가 RoI 풀링 전의 계층들에 적합하지만 처음부터 훈련하는 경우에는 그렇지 않기 때문이다.
즉, 처음부터 Detection network를 훈련하려면 Proposal이 없는 프레임 워크가 필요하다. 실제로 DSOD는 SSD에서 멀티 스케일 프레임워크를 도출할 수 있다. 이는 빠른 처리 속도와 함께 높은 정확도에 도달 할 수 있기 때문이다.
원칙 2: Deep Supervision.
심층지도 학습의 효과는 GoogLeNet, DSN, DeepID3 등에서 입증되었다. 핵심 아이디어는 통합된 목적 함수를 Output Layer에서 뿐만이 아닌, 이전 Hidden Layer에 대한 직접적인 감독을 통해 제공하는 것이다. 여러 은닉 계층에서 이러한 목적 함수를 활용한 "동반하는 값"또는 "보조하는 값"은 기울기 소실 문제를 완화할 수 있다. 이 "동반 값" 목적 함수를 각 은닉 계층에 도입하기 위해선 복잡한 부차 출력 계층을 추가해야만 한다.
DSOD는 DenseNets에 소개된 dense layer-wise connection으로 심층 감독을 강화한다. 블록의 모든 선행 레이어가 현재 레이어에 연결된 경우 이 블록을 Dense 블록이라고 한다. 따라서 DenseNet의 이전 계층은 Skip Connection을 통해 목적 함수에서 추가 감독이 가능하다. 다시 말해, 네트워크 상단에는 단 하나의 손실 함수만 필요하지만 이전 계층을 포함한 모든 계층은 감독된 데이터를 공유할 수 있다.
뒤에서 서술할 풀링 레이어가 없는 Transition Layer에서 심층 감독의 이점을 확인할 수 있다. 피쳐 맵 해상도를 유지하면서 Dense 블록 수를 늘리기 위해 이 레이어(풀링 레이어가 포함되지 않은 Transition Layer)를 도입였는데, DenseNet의 원래 디자인에서 각 Transition layer에는 피쳐 맵을 다운 샘플링하는 풀링 작업이 포함되어 있다. 그 때문에 동일한 사이즈의 출력을 유지하려는 경우 Dense 블록의 수를 고정해야만 했고, 네트워크 깊이를 늘리는 유일한 방법은 DenseNet의 각 블록 내에 레이어를 추가하는 것이었다. 하지만 풀링 레이어가없는 Transition layer는 DSOD 아키텍처의 Dense 블록의 수에 대한 이러한 제약을 제거하였으며, 기존의 DenseNet에서도 사용할 수 있다.
원칙 3: Stem Block.
저자가 Inception-v3 및 v4에서 영감을 받았다는 Stem 블록을 3개의 3x3 컨볼 루션 레이어와 2x2 최대 풀링 레이어의 스택으로 정의하였다. 첫 번째 conv-layer는 stride = 2로 작동하고 다른 두 개는 stride = 1로 작동한다. 이 간단한 줄기 구조를 추가하면 실험에서 감지 성능이 반드시 향상 될 것이다. DenseNet의 원래 디자인(7x7 conv-layer, stride = 2, 3x3 max pooling, stride = 2)과 비교할 때 스템 블록은 기존 입력 이미지의 정보 손실을 줄일 수 있기 때문이라고 추측된다. 이 Stem 블록의 효과가 탐지 성능에 중요하다는 것을 뒤에서 볼 수 있다.
원칙 4: Dense Prediction Structure.
Learning Half and Reusing Half.
SSD와 같은 일반적인 구조(그림2 참조)에서 각 스케일은 인접한 이전 스케일에서 직접 전이된다. 이 논문에선 다중 스케일 정보를 융합할 수 있는 Dense structure를 제안하였다. 단순화를 위해 각 스케일의 출력이 동일한 수의 채널을 출력하도록 제한하였으며, DSOD에서 scale-1을 제외한 각 피쳐 맵의 절반은 일련의 conv-layer를 사용하여 이전 스케일에서 학습되고, 나머지 피쳐 맵은 인접한 고해상도 피쳐 맵에서 직접 다운 샘플링된다.
다운 샘플링 블록은 2x2, stride=2의 max pooling layer와 1x1, stride=1의 conv-layer로 구성한다. 풀링 계층은 해상도를 현재 크기에 맞추는 것을 연결 과정에서의 목표로 한다. 1x1 conv-layer는 채널 수를 50 %로 줄이는 데 사용된다. 풀링 레이어는 연산 비용을 절감하기 위해 1x1 conv-layer 앞에 배치된다. 이 다운 샘플링 블록은 이전의 모든 스케일에서 multi-resolution feature map을 사용하여 각 스케일을 가져 오며, 이는 본질적으로 DenseNets에 도입된 dense layer-wise connection과 동일하다. 각 스케일에서, 새로운 피쳐 맵의 절반만 학습하고 이전 피쳐 맵의 나머지 절반 을 재사용한다. 이 Dense prediction structure는 일반적인 구조보다 적은 매개변수로 더 정확한 결과를 산출 할 수 있다.
3.2. Training Settings
- Caffe 프레임 워크]를 기반으로 탐지기를 구현하였음
- 모든 모델은 NVidia TitanX GPU에서 SGD 솔버를 사용하여 처음부터 훈련되었음
- DSOD 피쳐 맵의 각 스케일은 여러 해상도에서 연결되기 때문에 L2 정규화 기술을 채택하여 모든 출력에서 피쳐의 표준을 20으로 조정하였음(SSD는이 정규화를 scale-1에만 적용하였음)
- 자체 Learning rate 및 미니- 배치 크기 설정을 제외한 BBOX 및 Loss Function을 포함하는 대부분의 학습 전략은 SSD를 따르며, 세부 사항은 실험 섹션에서 제공
4. Experiments
4.1. Ablation Study on PASCAL VOC 2007

4.1.1. Dense Blocks의 구성
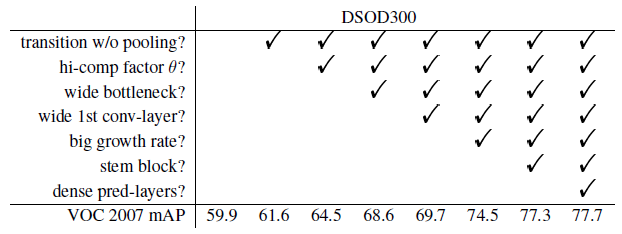
논문에선 먼저 Backbone의 하위 네트워크에 위치한 Dense 블록에서 다양한 구성의 상관관계를 조사하였다. 구성에 따른 결과는 위의 표2를 참고하면 된다.
[Transition 레이어의 압축 계수]
DenseNets의 Transition 계층에서 두 개의 압축 계수 값 (θ = 0.5, 1)을 비교한다. 결과는 표3의 2행과 3행에 나와 있다. 압축 계수 θ = 1은 Transition 레이어에서 피쳐 맵의 다운 사이징이 없음을 의미하는 반면 θ = 0.5는 피쳐 맵의 절반이 감소 함을 의미한다. 결과는 θ = 1일 때, θ = 0.5보다 2.9 % 더 높은 mAP를 달성한다는 것을 보여준다.
# 병목 레이어의 채널: 표3의 3행과 4행에서 볼 수 있듯이, 더 넓은 병목 계층(응답 맵 채널이 더 많음)이 성능을 크게 향상시키는 것으로 나타났다 (4.1 % mAP).
# 첫 번째 conv-layer의 채널: 첫 번째 conv-layer에있는 많은 수의 채널이 필요하다는 것을 확인할 수 있었으며, 1.1 % mAP 향상을 가져왔다. (표의 4 행과 5 행).
[Grouth rate]
grouth rate를 나타내는 k값이 클 수록 훨씬 더 좋은 성능을 내는 것이 밝혀졌다. 4k 병목 채널에서 k를 16에서 48로 증가 시키면 표의 5행과 6행에서 4.8 % mAP 개선이 관찰되었다.
4.1.2. 디자인 원칙의 효율성 증명
[제안과정이 필요없는 프레임워크]
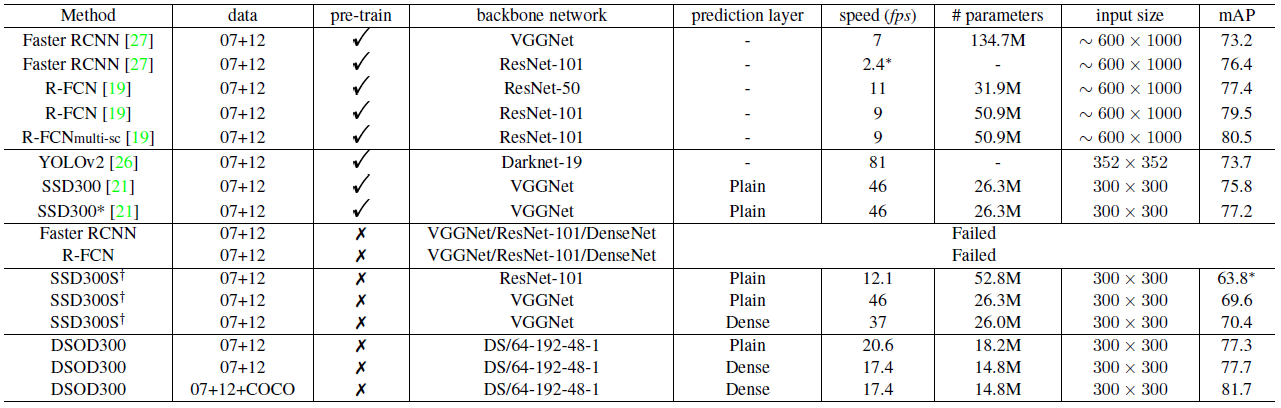
Faster R-CNN 및 R-FCN과 같은 제안 기반 프레임워크를 사용하여 객체 감지기를 처음부터 훈련한 프로세스는 시도한 모든 네트워크 구조(VGGNet, ResNet, DenseNet)에서 파라미터가 수렴하지 못하였다.
제안이 필요 없는 프레임워크인 SSD를 사용하여 객체 감지기를 학습 시키려고 했을 때는 학습은 성공적으로 수렴되었지만 표4에 표기된 것처럼 사전 학습 된 모델 (75.8 %)의 케이스에 비해 훨씬 더 나쁜 결과 (VGG의 경우 69.6 %)를 기록하였다. 이 실험은 Proposal-free를 활용하기 위한 설계 원칙을 검증하기 위해 시행되었다.
[Deep supervision]
논문에선 deep supervision을 통해 처음부터 물체 감지기를 훈련 시키려고 하였다. DSOD300은 77.7 % mAP를 달성하는데, 이는 VGG16 (69.6 %)을 사용하여 처음부터 훈련 된 SSD300S보다 훨씬 좋은 결과이다. 또한 SSD300 (75.8 %)의 미세 조정 결과보다 높은 결과를 보여주었다. 즉, Deep supervision의 원칙이 유효함을 입증했다고 볼 수 있다.
[풀링 레이어가 포함되지 않은 Transition]
제안된 레이어가 없는 경우(오진 3개의 Dense 블록만 존재)와 있는 경우(DSOD에서의 4개의 Dense 블록이 존재)를 비교하였다. Backbone 네트워크는 DS/32-12-16-0.5이며, 결과는 위의 표에 나와 있다. 풀링 계층이없는 Transition 블록이 있는 네트워크 구조는 1.7 %의 성능 향상을 가져와, 이 계층의 효율성을 입증하였다.
[Stem block]
표3의 6행과 9행에서 볼 수 있듯이 Stem 블록은 성능을 74.5 %에서 77.3 %로 향상시킨다. 즉 원본 이미지에서 정보 손실을 보호 할 수 있다는 추측을 입증하였다.
[Dense Prediction Structure]
속도/정확도/연산량의 세 가지 측면에서 Dense prediction 구조를 분석한다. 표4에서 볼 수 있듯이, DSOD는 추가 다운샘플링 블록의 비용으로 인해 기존 SSD보다 약간 느렸다.(17.4fps vs 20.6fps) 그러나 Dense 구조를 사용하면 mAP를 77.3 %에서 77.7 %로 개선하고 매개 변수를 18.2M에서 14.8M으로 줄일 수 있었다.(표3의 9행과 10행 참고)
또한 SSD의 예측 계층을 제안 된 Dense prediction 계층으로 교체했을 떄, 사전 학습 된 모델을 사용한 훈련에서 기존 SSD는 75.8 %에서 76.1 %로, 사용하지 않았을 때는 69.6 %에서 70.4 %로 향상 되었다. 즉, Dense prediction 레이어의 효과를 확인할 수 있었다.
[What if pre-training on ImageNet?]
pre-trained 된 ImageNet에서 하나의 light Backbone 네트워크 DS/64-12-16-1을 훈련 시켰는데, 검증 세트에서 66.8% top-1 정확도와 87.8 % top-5 정확도를 얻을 수 있었으며(VGG-16보다 약간 나쁨), “07 + 12” train val 세트에서 전체 프레임워크를 fine-tuning한 네트워크는 VOC 2007 테스트 세트에서 70.3 % mAP를 달성하였다. 이에 반해 training-from-scratch 솔루션은 70.7 %의 정확도를 달성하며 약간 더 좋은 결과를 보였다.