Gao, Chen, Yuliang Zou, and Jia-Bin Huang. "ican: Instance-centric attention network for human-object interaction detection." arXiv preprint arXiv:1808.10437(2018).
1. Abstract
사진을 보고 그 장면을 이해했다고 말하기 위해선 사람과 그 주변 물체가 어떤 상호작용을 하고 있는지에 대해 설명할 수 있어야 한다. 본 논문에서는 HOI(Human-object interactions)를 추론하는 작업을 주로 다루었다.
각 영역의 형상(appearance)에 interaction을 예측하기 위해 주의 깊게 확인해야 할 영역에 대한 정보가 포함되어 있다. 이를 Attention map이라고 하며, 본 논문에선 이 영역을 강조하는 방법을 학습할 수 있는 모듈을 제안하였으며 이를 활용하여 전체 Context를 예측한다.
2. Introduction
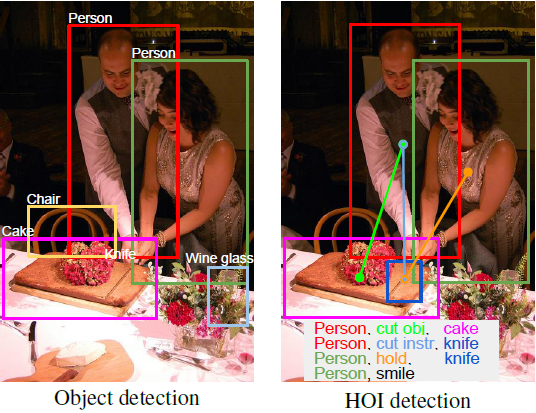
Why HOI?
위의 그림을 통해 HOI의 역할을 쉽게 이해할 수 있다. 입력 이미지와 감지기(Detector)에서 감지된 Attention region이 주어지면 이미지 내부의 모든 [사람, Verb(행동), 물체]의 triplet을 식별하는 것을 목표로 한다.
HOI는 "어디에 무엇이 있는가?"의 관점이 아닌 "무슨 일이 일어나고 있는가?"에 초점을 맞춘 작업이라고 생각하면 이해가 편하다. 해당 기술을 연구하는 것은 Pose estimation, Image captioning, Image retrieval 등의 높은 수준의 작업에 대한 단서로 작용할 수 있다.
Why Attention map?
최근 연구에선 사람과 물체의 형상이 어떤 영역에 관련이 있는지를 활용한다. 즉, 사람의 외형적 특징과 함께 동작을 인지하는 알고리즘을 사용한다면 더 정확한 문맥 추론이 가능할 것이다.
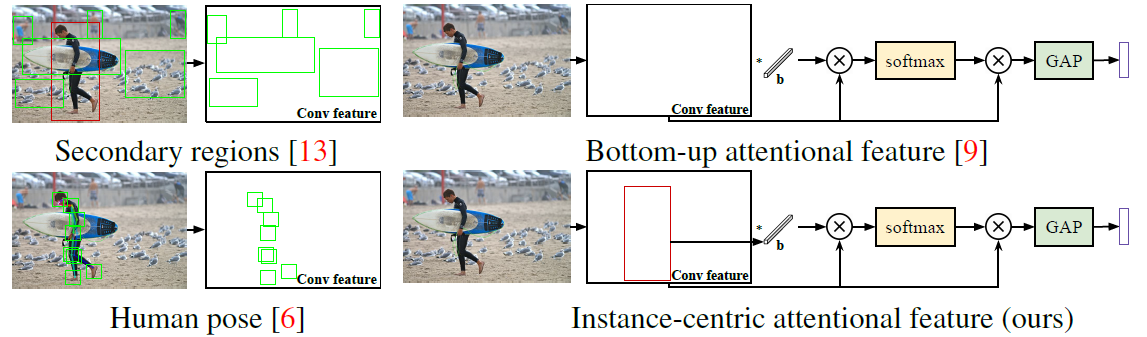
예를 들어 위의 사진을 살펴보면 Context를 추측하기 위한 다양한 알고리즘들이 소개되어 있다. Secondary regions의 활용, 사람과 물체의 바운딩 박스의 결합 사용, 사람의 포즈의 키포인트 주변의 Feature 추출 등이 활용될 수 있다.
이와 같은 방법들로 추출된 Context를 통합하여 Attention map을 구성한다면 당연히 성능이 향상될 것이다. 하지만 이 방식은 딥러닝으로 자동화 된 Attention map을 예측하는 기술이 아니며 사람이 직접 Attention region을 설정하는 방식이다. 이렇게 생성된 Map은 동작/상호작용을 인지하는 작업에 완벽할 수 없다. 상황마다 집중(Attention)할 영역이 달라지기 때문이다.
예를 들어, '던지기'나 '타기'와 같은 동작을 식별하기 위해선 사람의 자세를 봐야할 것이고, '컵으로 마시기', '숟가락으로 먹기'와 같은 손과 물체의 상호작용과 관련된 동작을 인식하기 위해선 상호작용에 초점을 두어야 하며, '라켓으로 공을 치는 것'이나 '배트로 야구공을 타격하는 것'은 전체적인 배경에 집중해야 할 것이기 때문이다.
최근 연구에서는 위의 한계를 해결하기 위하여 행동 인식 또는 이미지 분류를 위해 훈련 가능한 end-to-end Attention 모듈을 활용한다. 하지만 이러한 방법은 인스턴스 수준이 아닌 이미지 수준의 분류 작업을 위하여 설계되었다.
3. Instance-Centric Attention Network
본 논문에선 HOI scores를 다음과 같은 식으로 계산한다.

$S^a_{h,o}$ : HOI score
$s_h, s_o$ : FasterRCNN으로 검출된 사람과 물체의 Confidence score
$s^a_h, s^a_o$ : 검출된 형상(appearance)에 기반한 사람과 물체의 interaction score [Object/Human stream]
$s^a_{sp}$ : 사람과 물체 사이의 spatial 관계에 기반한 interaction score [Pairwise stream]
$s_h$는 FasterRCNN으로 검출된 사람의 confidence score이며 $s_o$는 물체의 confidence score이다. 사람의 행동을 예측할 때 웃는 사람 등 물체가 없는 경우도 검출할 수 있어야 하는데, 이 상황에서 HOI scores는 $S^a_{h,o} = s_h \centerdot s^a_h$가 된다.
3.1 Instance-centric attention module

- 해당 모듈에선 FasterRCNN을 활용하여 생성한 Feature map(FM)을 활용하여 Context를 뽑아내는 과정이 이루어진다. 우선 FM에서 ROI pooling, res5 block, Global average pooling을 거쳐 인스턴스 레벨의 사람의 형상인 $x^h_{inst}$를 추출한다.
- 추출된 $x^h_{inst}$는 FC layer를 통과하여 512-dimensional 벡터가 되어 다시 FM과 dot production을 수행하여 유사도를 계산한다. 이후 softmax를 적용하여 Attentional map을 추출할 수 있다.
- 이 Attentional map과 기존 이미지를 dot production하면 HOI 작업에 활용할 수 있는 highlighting된 map을 구할 수 있다. 결과 값 역시 GAP를 거치고 FC 레이어를 거쳐 $x^h_{context}$ context 벡터를 만들며 이는 앞에서 구한 인스턴스 레벨의 $x^h_{inst}$ 벡터와 연결되어 사용된다.
- 이 벡터를 활용하여 $s^a_h, s^a_o$를 구할 수 있다.
이렇게 구성된 iCAN 모듈은 두 가지 장점이 있는데,
첫째, 다양한 알고리즘을 적용한 결과를 토대로 손으로 설계해야만 하는 Attention map과 달리 자동으로 Attention map을 생성하고 성능 향상을 위해 훈련될 수 있다.
둘째, image-level의 모듈과 비교하였을 때 instance-centric attention map은 다른 영역에 더 주의를 기울일 수 있으므로 더 유연한 활용성을 보인다.
3.2 Multi-stream network

위의 그림을 보면 네트워크는 총 세 가지 stream(object, human, Pairwise stream)로 구성되어 있는 것을 볼 수 있는데, 3.1에서 본 과정이 Object/Human stream에 해당하는 과정이며 binary sigmoid를 통과시켜 최종 HOI score를 계산하기 위한 식에서 $s^a_h$와 $s^a_o$를 계산할 수 있었다.
Pairwise stream에서는 two-channel binary image representation을 채택하여 상호작용 패턴을 추출한다. 사람과 물체의 바운딩 박스의 합집합을 reference box로 활용하여 그 안에서 두 개의 채널을 활용하는 방식이다. 첫 번째 채널은 사람 바운딩 박스 안에서 값 1을 가지며 다른 곳에서는 0을 갖고, 두 번째 채널은 물체 바운딩 박스 안에서 값 1을 가지며 다른 곳에서는 0을 갖는다. 그 후 CNN을 활용하여 이 2채널 이진 이미지에서 spatial feature를 추출한다.
하지만 이 작업만으로는 정확한 동작 예측이 불가능하므로 인스턴스 레벨의 사람의 형태인 $x^h_{inst}$와 연결하여 binary sigmoid를 통과시켜 $s^a_{sp}$를 구한다. 그 이유는 사람의 형태가 비슷한 레이아웃(예를 들어 자전거를 옮기는 사람과 자전거를 타는 사람)에서 다른 행동을 판단하는데 도움이 되기 때문이다.