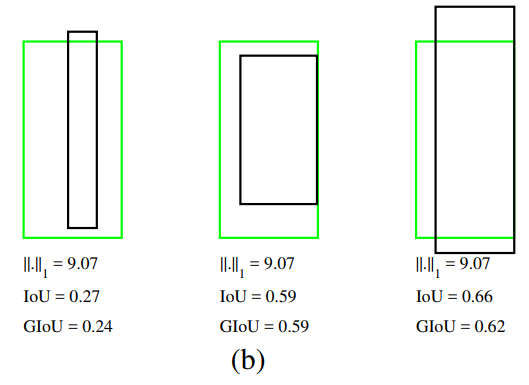
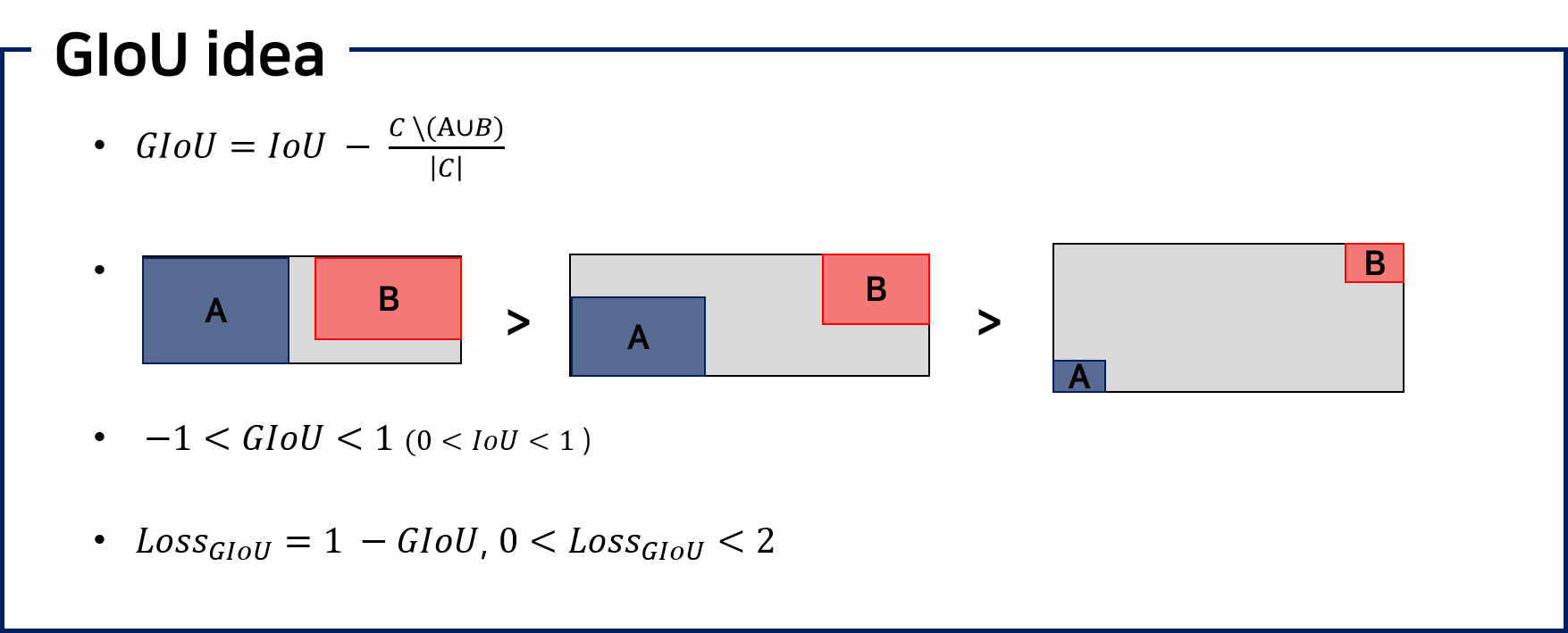
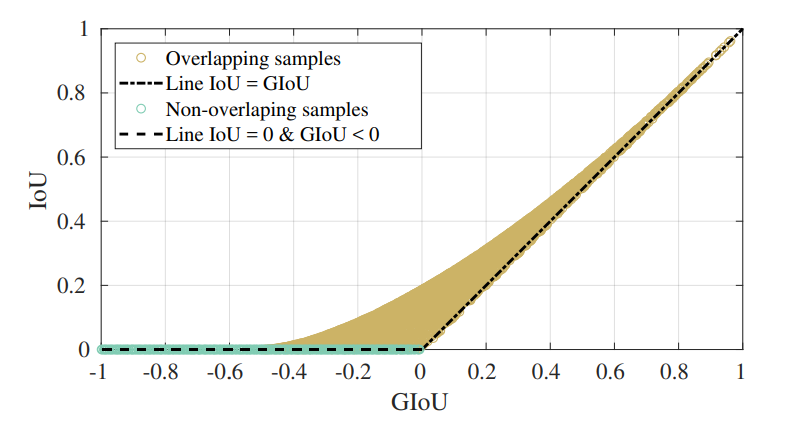
* 이 논문은 기존의 Convolution filter의 곱 연산을 가산(Adder)로 대체하여 연산량을 대폭 줄였으나 정확도는 유지하였다.
* 2019년 Computer Vision and Pattern Recognition 저널에 등재되었다.
* 21년 2월 23일 기준 26회 인용되었다.
1. Introduce
기존의 대부분의 Convolution Networks는 입력과 Convolution Filter 사이의 곱 연산을 통해 Weight를 업데이트 한다. 하지만 이 방식은 많은 GPU 메모리를 소모할 뿐만 아니라 많은 전력을 소비하기 때문에 휴대용 장비에서 사용하기 어렵다. 이를 보완한 MobileNet 등이 제안되어 왔지만, 곱 연산 때문에 많은 연산량이 필요하다는 점은 변하지 않았다.
이 논문에서 제안한 Adder를 활용한 네트워크는 처음 나온 아이디어가 아니다. 이진화를 활용한 binarized filter 등을 활용한 binary adder 기법들이 소개되어 왔으며, 나름 준수한 성능을 보였다. 하지만 이진화 아이디어는 기존 네트워크의 mAP를 보존할 수 없고, 수렴 속도와 학습률이 저하되는 등 훈련 절차가 안정적이지 않다. 또한, 연구원들은 기존 Convolution Filter가 익숙하고, 연산을 빠르게 만드는 기법을 도입하는 것에 익숙하다.
2. 곱셈을 포함하지 않은 네트워크

위의 그림을 보면 AdderNet과 기존 CNN과의 차별점을 쉽게 파악할 수 있다. CNN의 경우 각도로서 Class를 분류하지만, AdderNet은 군집화 된 점의 좌표를 활용하여 클래스를 분류한다. 그 이유는 CNN은 필터와 입력 간의 cross correlation을 계산하는데, 그 값들이 정규화되면 컨볼루젼 연산은 두 벡터 간의 코사인 거리를 계산하는 것과 같다. 이것이 각도로서 Classification을 하는 이유이다. 반면에 AdderNets이 $l_1 norm$을 활용하여 class를 분류하기 때문에 각각 다른 중심을 가진 포인트로 군집화 된다. 이 Visualize 결과를 봤을 때, $l_1$ distance는 심층 신경망에서 필터와 입력값 사이의 유사도로서 사용할 수 있다.
기존의 컨볼루젼 필터 F는 $F \in \mathcal{R}^{d \times d \times c_{in} \times c_{out}}$로 고려되고, 입력값은 $X \in \mathcal{R}^{H \times W \times c_{in}}$로 나타낼 수 있다. 여기서 각각 d는 필터의 커널 사이즈와 같고, $c_{in}$은 입력 채널, $c_{out}$은 출력 채널을 의미한다. H와 W는 각각 입력의 특성 값이다. 이를 활용하여 기존의 컨볼루젼의 연산은 다음과 같이 표현할 수 있다.
(Eq.1) $$ Y(m,n,t) = \sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{in}}S(X(m+i,n+j,k), F(i,j,k,t)) $$
S는 사전에 정의된 유사도 측정 함수이며, 이 방식을 활용한 대부분의 네트워크는 덧셈보다 연산량이 많은 곱셈을 사용한다.
2.1. Adder Networks
저자는 위에서 함수 S를 제거하고 아래와 같은 수식을 정의하였다.
(Eq.2) $$ Y(m,n,t) = -\sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{in}}|(X(m+i,n+j,k) - F(i,j,k,t))|$$
덧셈은 $l_1$ distance을 측정하기 위한 방법으로서 도입되었다. 뺄셈 역시 보수 코드를 활용하여 덧셈으로 통합된다. $l_1$ distance는 효율적으로 필터와 피쳐 간의 유사도를 계산할 수 있게 한다. 두 가지 모두 유사도를 계산할 수 있는 식이며, 출력값에 약간의 차이를 보인다. Conv Filter의 출력은 양수 또는 음수일 수 있지만, Adder의 출력은 항상 음수이다. 이 부분은 Batch Normalization Layer를 활용하여 정규화 함으로서 문제를 해결한다. 이 정규화 계층에도 곱셈이 포함되어 있지만 그 연산량은 Conv Layer에 비하면 한참 낮다. 결국 Convolution layer를 Adder layer로 대체함으로서 AddNets을 구성할 수 있다.
2.2. 최적화
신경망은 역전파를 사용하여 필터의 기울기를 계산하고 확률적 기울기 하강법(Stochastic gradient descent method)을 사용하여 매개변수를 업데이트한다. CNN에서 필터 F에 대한 출력 특성 Y의 편미분은 다음과 같이 계산된다.
(Eq.3) $$ \frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)} = X(m+i,n+j,k), (i \in [m, m+d], j \in [n, n+d]) $$
AdderNets에서도 역전파할 기울기가 필요하기 때문에 SGD에서 계산된 기울기 값을 활용한다. 여기서 F에 대한 Y의 편미분은 다음과 같이 계산할 수 있다.
(Eq.4) $$ \frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)} = sgn(X(m+i,n+j,k)-F(i,j,k,t)) $$
sgn은 부호 함수를 뜻하기 때문에 기울기의 값으로 오직 +1, 0, -1만을 취할 수 있다. 그러나 위의 signSGD는 대부분의 경우 가장 가파른 기울기를 가지는 하강 방향을 취하지 않으며 차원이 커질 수록 악화되는 모습을 보인다. 즉, signSGD는 신경망 최적화에 적합하지 않다고 할 수 있다. 이러한 단점을 고려한 상태에서 여기서 $l_2-norm$을 활용한다고 생각해보자.
(Eq.5) $$ \frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)} = X(m+i,n+j,k)-F(i,j,k,t) $$
위의 수식은 기존 signSGD과 연결시킬 수 있는 업데이트 된 $l_2-norm$ 기울기이다. 이 식이 결국 저자가 주장한 핵심 수식이며, 이후부턴 FPG(Full-precision Gradient)라고 부르겠다.
필터의 기울기 외에도 입력 피쳐인 X 역시 매개변수 업데이트에 중요한 역할을 한다. 레이어 $i$의 필터와 입력을 $F_i, X_i$라고 했을 때, $F_i$ 자체의 기울기에만 영향을 주는 $\frac{\partial Y}{\partial F_i}$와 달리 $\frac{\partial Y}{\partial X_i}$는 기울기 연쇄법칙에 따라 $i$ 이전 레이어의 기울기에도 영향을 줄 수 있다. 이 때 위에서 제시한 FPG를 활용하여 기울기 역전파를 수행하려고 보니, 계산된 기울기 값이 [-1,1] 범위를 넘기 때문에 기울기 폭파(Gradient exploding) 현상이 발생할 수 있다는 문제가 발생한다. 이를 아래의 Hard Tanh 함수를 통해 해결할 수 있다.
(Eq.6) $$ \frac{\partial Y(m,n,t)}{\partial F(i,j,k,t)} = HT(F(i,j,k,t)-X(m+i,n+j,k)) $$
여기서 HT함수는 다음과 같다.
(Eq.7) $$ \begin{align} HT(x) = \begin{cases} x & if & -1 < x< 1\\ 1 & & x > 1 \\ -1 & & x < -1 \end{cases} \end{align} $$
2.3. 적응형 Learning rate scaling
기존 CNN에서 가중치와 입력 피쳐가 독립적이고 정규 분포에 따라 동일하게 분포한다고 가정하면 출력의 분산은 다음과 같이 계산할 수 있다.
(Eq.8) $$ \begin{align} Var[Y_{CNN}] &= \sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{in}} Var[X \times F] \\ &=d^2c_{in}Var[X]Var[F] \end{align} $$
가중치의 분산이 $Var[F]=\frac{1}{d^2c_{in}}$가 되면 출력의 분산이 입력의 분산과 일치하여 신경망의 정보 전달 흐름에 도움이 된다. 이와 대조적으로, F와 X가 정규분포를 따를 때 AdderNets의 출력의 분산은 다음과 같이 근사할 수 있다.
(Eq.9) $$ \begin{align} Var[Y_{AdderNet}] &= \sum_{i=0}^{d} \sum_{j=0}^{d} \sum_{k=0}^{c_{in}} Var[|X - F]] \\ &=\sqrt{\frac{2}{\pi}}d^2c_{in}(Var[X] + Var[F]) \end{align} $$
일반적으로 Var[F]은 작은 값(CNN에선 $10^{-3}$ 또는 $10^{-4}$)을 가지므로 소수의 곱셈을 취하는 CNN에서의 가중치의 분산은 작아진다. 하지만 덧셈 연산을 활용하는 AdderNes에서는 대부분 CNN 대비 훨씬 더 큰 분산을 취하게 된다.
다음으로 AdderNets이 가지는 더 큰 분산의 영향을 알아보자. 활성화 함수의 효율을 높이기 위해 가산기 계층 이후에 배치 정규화 레이어를 추가한다. 미니배치 $B = \{x_1, …, x_m\}$에 대한 입력 x가 주어졌을 때 배치 정규화 계층은 다음과 같이 표현할 수 있다.
(Eq.10) $$ y = \gamma \frac{x - \mu_\mathcal{B}}{\sigma_\mathcal{B}} + \beta $$
여기서 $\gamma$와 $\beta$는 학습되는 파라미터이고, $\mu_\mathcal{B} = \frac{1}{m} \sum_{i}x_i$와 $\sigma^2_\mathcal{B} = \frac{1}{m} \sum_{i} (x_i - \mu_\mathcal{B})^2$은 각각 미니배치의 평균과 분산을 표현한 수식이다. $x$에 대한 손실 $\ell$의 기울기는 다음과 같이 계산된다.
(Eq.11) $$ \frac{\partial \ell}{\partial x_i} = \sum_{j=1}^{m} \frac{\gamma}{m^2\sigma_\mathcal{B}}{\frac{\partial \ell}{\partial y_i} - \frac{\partial \ell}{\partial y_j}[1 + \frac{(x_i-x_j)(x_j-\mu_\mathcal{B})}{\sigma_\mathcal{B}}]} $$
(Eq.9)에서 더 큰 분산 $Var[Y]=\sigma_\mathcal{B}$가 주어질수록 AdderNets의 X에 대한 기울기의 크기는 (Eq.11)에 따른 CNN에서의 경우보다 훨씬 작을 것이며, 연쇄법칙에 의해 AdderNets의 필터의 기울기의 크기가 감소할 것이다.(분산이 커지는 것은 데이터가 넓게 펼쳐진 정규 그래프를 이룬다는 말이며, 결국 기울기가 작아지는 것과 같다.)

위의 표는 MNIST 데이터 세트에 CNN과 AdderNets을 활용하여 LeNet-5-BN에서 $||F||_2$의 기울기의 $\ell_2$-norm을 정리한 표이다. BN은 배치 정규화 계층을 추가했다는 뜻이며, 첫번째 iteration에서의 결과를 토대로 작성되었다. 이 표에서 볼 수 있듯이 AdderNets의 필터의 기울기 값이 CNN의 경우보다 훨씬 작기 때문에 업데이트 속도가 느리다. 이를 보완하기 위해 더 큰 학습률을 채택하면 될 듯 싶지만, 표에서 볼 수 있듯이 기울기의 norm 값은 계층마다 크게 달라지는 모습을 보이고, 이에 따라 필터의 특성을 고려한 학습률 선택이 필요하단걸 알 수 있다. 때문에 제안된 Adaptive Learning Rate(ALR)는 아래와 같다.
(Eq.12) $$ \Delta F_l = \gamma \times \alpha_l \times \Delta L(F_l) $$
여기서 $\gamma$는 Local 학습률(가산기와 BN에 적용되는 값과 같음)이고, $\Delta L(F_l)$은 레이어 $l$의 필터의 기울기이며, $\alpha_l$은 Local 학습률(해당 레이어에만 적용)이다. AdderNets에서 필터는 입력과의 차이를 계산하므로 그 크기는 입력에서 의미있는 정보를 추출하는 데에 더 적합하다. 배치 정규화 레이어로 인해 서로 다른 계층의 입력 크기가 정규화되며, 서로 다른 계층의 필터 크기에 대한 정규화가 이루어진다. 따라서 Local 학습률은 다음과 같이 정의할 수 있다.
(Eq.13) $$ \alpha_l = \frac{\eta \sqrt{k}}{||\Delta L(F_l)||_2} $$
k는 $\ell_2$-norm을 평균화하기 위해 사용되는 $F_l$의 요소 수를 나타내며, $\eta$는 가산기 필터의 학습률을 제어하는 하이퍼 파라미터이다. 제안된 Adaptive Learning Rate 스케일링을 활용하면 서로 다른 계층의 가산기 필터를 거의 동일한 단계로 업데이트 할 수 있다.
정리하면 알고리즘은 다음과 같다.
- Algoritm is repeated for (convergence):
|
3. Experiment
이 논문에선 MNIST, CIFAR 및 ImageNet을 포함한 여러 벤치마크 데이터셋에서 AdderNet의 효과를 검증하기 위한 실험을 구현하였다. 이와 관련된 Ablation study(머신러닝에서 구성 레이어를 제거하였을 때의 전체 성능에 미치는 영향에 대한 통찰을 얻기 위한 실험) 및 특징 시각화가 이 섹션에 삽입되었다. 실험은 Pytorch 환경에서 NVIDIA Tesla V100 GPU를 활용하여 진행되었다.
3.1. Experiment on CIFAR

위의 표는 32x32 RGB 컬러 이미지로 구성된 CIFAR-10와 CIFAR-100 데이터셋의 Classification 결과이다. 초기 학습률은 0.1로 설정하였으며, polynomial learning rate schedule(keras 내부 함수)을 따랐다. 모델은 400 epochs 동안 256개의 배치 사이즈로 나뉘어 훈련되었다. AdderNets은 곱셈없이 CNN과 거의 비슷한 결과를 달성했지만 XNOR 연산을 활용한 BNN(Binary Neural Network)의 경우는 모델 크기는 오히려 AdderNets보다도 작지만 정확도가 훨씬 떨어진다. ResNet20에서 CNN이 역시 가장 좋은 결과를 보이지만 곱셈이 많이 포함되어 연산량이 가장 많으며, ResNet32에서는 AdderNets와 거의 성능 차이가 없는 모습을 보인다.
3.2. Experiment on ImageNet

224x224 RGB걸러의 이미지로 구성된 ImageNet의 데이터셋에 대한 실험 결과이다. ResNet-18을 사용하여 평가되었으며, 코사인 학습률 감소법을 활용하여 150 epochs 동안 훈련하였다. 네트워크들은 NAG(Nesterov Accelerated Gradient)를 사용하여 최적화 되었으며 가중치 감소와 모멘텀은 각각 $10^{-4}$와 0.9로 설정되었다. 배치 사이즈는 256을 사용하였고, 나머지 하이퍼 파라미터들은 CIFAR 데이터셋 실험과 같게 적용되었다. 실험 결과 ResNet-18에선 BNN은 낮은 정확도를 보였으나, 상대적으로 AdderNets은 높은 정확도를 보였으며, ResNet-50으로 구성된 네트워크에선 CNN과 비슷한 성능을 냄을 볼 수 있다.
3.3. Visualization Results
3.3.1. Filters

필터를 볼 때 AdderNets과 CNN의 유사성을 볼 수 있는데, LeNet-BN 네트워크 필터를 시각화한 위의 사진에서 AdderNets과 CNN은 다른 metric을 사용함에도 필터의 패턴이 비슷한 것을 볼 수 있다. 결국, 곱셈없이 덧셈으로만 저비용으로 고효율을 낼 수 있다.
3.3.2. weights

위의 그림에서, AdderNets은 Laplace 분포에 가깝고 CNN은 가우시안 분포에 가까워 보인다. 실제로 $\ell_1$-norm은 Laplace 분포를 따르고, $\ell_2$-norm은 Gaussian 분포를 따른다.
3.4. Ablation study
이 섹션에선 가산 필터를 사용하여 AdderNets의 여러 계층을 처리하기 위한 적응형 학습률 스케일링을 설계하는 과정을 설명하였다. 먼저 학습률을 변경하지 않았을 때, LeNet-5-BN을 훈련시키고 FPG와 Sine Gradient를 사용하여 54.91% 및 29.26의 정확도를 얻었다. 기울기가 매우 작기 때문에 네트워크를 거의 훈련할 수 없었으며, 학습률을 상향할 필요가 있었다. 가산기 필터의 학습률을 100만큼 증가시키고 FPG를 사용하여, 풀 [10, 50, 100, 200, 500]의 다른 값과 비교하며 최고의 성능을 달성할 수 있었다. 아래 그림에서 적응형 학습률(Adaptive Learning Rate, 이하 ALR) 및 증가된 학습률(Increased Leraning Rate, 이하 ILR)을 사용하는 AdderNets은 Sign Gradient를 활용하여 97.99% 및 97.72%의 정확도를 달성하였지만 CNN의 정확도(99.40%)엔 미치지 못했다. AdderNets에서 ILR을 활용한 AdderNets은 FPG를 사용하였을 때 98.99%의 정확도를 달성하였으며, ALR을 활용했을 때는 99.40%의 정확도를 달성하였다. 즉, ALR이 더욱 효과적이었다.

4. Conclusions
이 논문에서 얻을 수 있는 것은 연산량이 많은 곱셈 방식을 가산기로 대체 할 수 있다는 가능성이다. 실제로 논문에선 가산기를 활용한 CNN의 성능과 유사한 성능에 도달하였으며 Full Precision Gradient 기법을 제안하였다. 특히, Adaptive Learning Rate를 도입하여 FPG의 문제점을 해결한 부분 역시 인상적이었다. 연산량을 줄여 알고리즘의 처리속도를 빠르게 할 수 있다면, 기존 FPS와 mAP가 반비례하는 성질을 해소하여 실시간 처리가 필요한(특히 자율주행) 분야에 큰 도움이 될 수 있을것이라 생각한다. 하지만 실험에서 사용한 이미지들의 크기가 작은 것으로 보아 큰 사이즈의 이미지를 처리하는 RCNN류 등의 알고리즘에도 성능 저하 없이 적용할 수 있는지는 검증이 필요하다.
5. Reference
Chen, Hanting, et al. "AdderNet: Do we really need multiplications in deep learning?." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.