RNN 계열의 알고리즘에 대해 공부하다가 Attention mechanism에 대해 접하게 되었다. 하지만 대부분의 자료를 보고는 원리를 이해하기 매우 어려웠는데, 이를 이해하기 쉽게 설명해놓은 유튜브 영상을 접하여 정리하여 포스팅한다.
1. Attention mechanism 도입의 배경
기존 RNN 방식은 연속적인 데이터를 처리하는데 특화된 알고리즘으로서 각광을 받았지만, 몇가지 문제점을 가지고 있었다.
Sequence로 입력을 모두 받은 후에 Decoding을 하는 방식이기 때문에 병렬화가 불가능하다.
고정된 크기의 Context 벡터에 모든 입력 값에 대한 정보를 압축하여 집어넣기 때문에 긴 데이터를 처리할 때 병목현상이 발생하여 정확도가 하락하게 된다.
관련 노드와의 거리가 멀어지면 Long-term dependency 특성에 의해 예측에 문제가 생긴다.
여기서 Long-term dependency 특성이란, 현재 Decoding하고 있는 영역과 그에 관련된 정보를 포함한 영역 간의 노드간 거리가 멀어질 경우, 입력 데이터의 특성이 일부 소실되었을 가능성이 커져서 그 특성을 제대로 반영하지 못하는 특성이다. 우리는 이러한 특성을 쉽게 접할 수 있는데, 주로 사용되는 분야인 번역 분야에서 굉장히 긴 문장이 입력으로 주어질 경우에 문장의 번역이 제대로 되지 않는 것이 이에 해당한다.
2. Attention mechanism이란?
포커싱에 따른 사진의 변화의 대표적인 예. Background out focusing이라고도 한다.
Attention mechanism은 영상처리 분야에서 등장한 개념이다. 사람의 눈은 자신이 보고자 하는 것에 초점을 맞춰서 봄으로서 마치 필요한 정보에 가중치를 두고 처리하는 듯한 구조를 가진다. 카메라에도 이러한 기능이 탑재되어, 원하는 부분에 포커싱이 되고 기타 영역은 블러 처리가 된 사진을 쉽게 찾을 수 있다.
이러한 구조를 RNN 계열의 알고리즘을 활용하는 것에 활용하겠다는 것이 도입의 배경이며, 만약 문장을 번역하는 데에 활용된다면 지금 번역하고 있는 단어에 따라 어떤 입력된 단어에 "주목"할 지를 가중치로서 계산하여 활용하는 것이 Attention mechanism이다. Encoder에서 나온 각각의 RNN cell의 state를 반영하며, Decoder 내부에서 가변적인 크기를 갖는 Context 벡터를 생성하여 활용하기 때문에 입력 Sequence의 길이에 영향을 적게 받는다.
3. Attention mechanism의 작동 구조
Attention mechanism을 도입한 이후부터 대부분의 RNN 계열의 시스템에는 이를 활용하는 추세다. 하지만 Attention mechanism의 작동 방법을 이해하기 쉽지 않았는데, 유튜브에 잘 정리된 자료가 있어 빌려 사용한다. 허민석 유튜브 채널의 “[딥러닝 기계번역] 시퀀스 투 시퀀스 + 어텐션 모델“을 참고하였으며,뒤에 링크를 추가하였다.
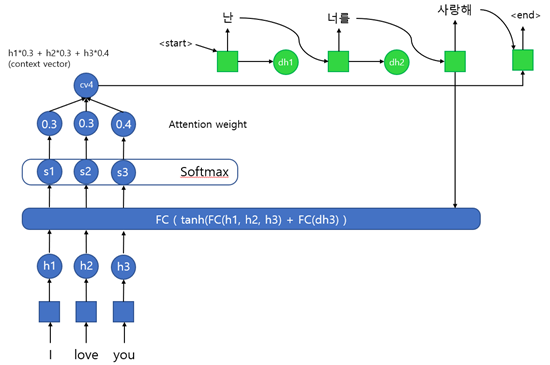
앞의 RNN을 번역 분야에서 사용하는 것을 예로 들었는데, 이번엔 Attention mechanism을 활용하여 번역하는 과정을 보이며 설명하겠다.
마찬가지로 입력으로 I love you라는 문장이 통째로 들어간다. 입력은 단어 단위로 히든 레이어를 통과시켜 h1, h2, h3 값을 구한다. 이 값들은 Alignment model의 입력 값으로 활용한다. 원래는 h1, h2, h3 값과 함께 이전 출력 값에 대한 정보인 dh 값이 입력으로 들어가야 하지만, 첫 번째 사이클에선 이전 출력 값이 존재하지 않기 때문에 h3 값을 입력으로 넣어준다.
Alignment model은 이 각각의 h1, h2, h3 값과 이전 출력 값과의 관계를 통해 어떤 단어에 집중하여 번역되어야 하는지에 대한 정보를 구하기 위해 작동한다. 때문에 내부를 살펴보면 Fully connected layer를 활용하여 유사도를 계산하는 것을 확인할 수 있다. 유사도를 구하기 위한 모델은 다양하게 존재한다고 한다. 계산되어 나온 이 유사도를 Attention score라고 한다.
이후 Attention score를 Softmax 함수를 활용하여 합이 1인 확률 값으로 만들어준다. 이 값을 Attention weight라고 하며 각 단어가 출력에 영향을 미치는 정도를 나타내는 가중치로 사용된다. (일부 블로그에서 이를 Attention score라고 하는 것을 봤는데, 이는 부르기 나름이기 때문에 크게 신경 쓰지 않아도 된다.)
각각의 Attention weight는 앞의 h1, h2, h3과 곱해진 후 합쳐져서 context vector를 구성한다. 즉, context vector는 각각의 사이클마다 다르게 계산되며, 크기에 제한이 없다는 것을 확인할 수 있다. 이 context vector는 이전의 출력 값(y)와 연결되어 비선형 함수를 통과하여 최종 출력 값을 계산하는데 사용된다.
첫 사이클에선 이전 출력 값이 없기 때문에 <start> 신호와 함께 연결되어 출력 값을 계산하는데 앞에서 현재의 출력과 연관이 가장 높은 단어가 “I” 였기 때문에 이를 번역한 “나”라는 단어를 배치하게 되고, start 신호로 현재 출력하는 자리가 주어 자리라는 정보를 받아 “난”으로 변환하여 출력하는 방식이라고 생각하면 이해하기 편하다.
최종 레이어의 출력은 다시 Alignment model에 입력으로 들어가며, 앞의 과정을 반복하게 된다.
이 과정을 거친 후에 작업이 완료되면 end값을 반환하고 작업을 마치게 된다. 아래의 그림은 어떤 단어끼리 관련이 있고 없는지에 대한 집중도를 plot한 그림이다. 이를 활용하면 특정 단어를 번역할 때 어떤 단어를 참고하여 번역해야 하는지에 대한 지표를 반영한 출력 값을 반환할 수 있다. 즉, Seq2Seq 네트워크의 긴 문장이 입력으로 들어왔을 때 처리하기 힘들다는 치명적인 단점을 극복하는데 활용이 가능하다.
4. Reference
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
최신 네트워크는 ImageNet과 같은 대규모 데이터셋에 의해 사전 훈련된 Backbone의 성능에 크게 의존적이다. 모델의 Fine-tuning을 활용하여 모델의 Transfer Learning을 활용한 이식에서 발생한 약간의 편향을 완화 가능하나, 근본적인 해결은 불가능하다. 또한, 다른 도메인 간의 모델 교환은 더욱 어려운 상황에 처하게 한다는 문제도 존재한다. 예를 들면 RGB image의 감지기로 사용되던 네트워크를 Depth image를 위한 모델로 활용하기 어렵다. 이 본문의 저자는 전이 학습을 사용하지 않고 처음부터 끝까지 훈련하는 방식을 제안하였다. 효율성을 극대화 하던 중, 일부 설계 원칙을 확립할 수 있었고, 계층 간의 조밀한 연결을 통해 활성화 된 Deep supervision이 우수한 검출기를 만들기 위해 중요한 역할을 한다는 것을 발견하였다. 실험은 Pascal VOC 2007, 2012와 MS COCO 데이터 셋을 활용하여 진행되었으며, SSD 기반의 네트워크를 구성하여 훈련하였다. 그 결과 Real time 기준을 만족시키면서 SSD의 성능을 능가하였다. 하지만 파라미터는 겨우 SSD의 1/2밖에 사용하지 않았다.
2. Introduction
대부분의 네트워크에서 활용하는 Transfer learning의 장단점은 아래와 같다.
* 장점
공개되어 있는 최첨단 딥-모델이 많고, 이걸 재사용하는 것은 매우 편리함.
Fine-tuning은 최종 모델을 빠르게 생성 가능하고, 라벨링 된 많은 데이터를 요구하지 않음.
* 단점
설계 가능한 여유 공간이 적음 : 사전 훈련 네트워크는 대부분 ImageNet 기반 분류기에서 가져온 것으로, 많은 파라미터가 모델에 포함되어 무겁다. 또한, 존재하는 Detector들은 직접 사전 훈련된 네트워크를 채택하여 사용하므로, 네트워크의 구조를 제어하거나 조정 혹은 수정하는데 제약이 존재한다. 또한 무거운 네트워크 구조에 의해 높은 컴퓨팅 성능이 요구된다.
학습 편향이 존재함 : 손실 함수와 분류 기준, Class의 수 등이 Backbone과 모두 다르기 때문에 최적의 값이 아닌, 다른 로컬 값으로의 수렴이 이어질 수 있다.
도메인의 불일치 : 2번의 문제는 Fine-tuning을 활용하여 다양한 클래스의 범주 분포로 인한 편향을 완화할 수 있다. 하지만 소스 도메인이 Depth image, 의료 영상 등의 아예 다른 도메인을 활용했을 때 잘못된 결과를 낼 수 있다.
이 논문은 다음 두 가지 질문으로부터 시작되었다.
첫째, 객체 감지 네트워크를 처음부터 훈련시킬 수 있을까?
둘째, 첫 번째 대답이 긍정적인 경우 높은 탐지 정확도를 유지하면서 물체 탐지를 위한 효율적인 네트워크 구조를 설계하는 원칙이 있을까?
저자는 이 질문의 답으로 처음부터 물체 감지기를 학습 할 수있는 간단하면서도 효율적인 프레임워크인 DSOD를 제안하였다. DSOD는 높은 호환성을 가졌기 때문에 서버, 데스크톱, 모바일 및 심지어 임베디드 장치와 같은 다양한 컴퓨팅 플랫폼에 대해 다양한 네트워크 구조를 조정할 수 있다는 장점을 가지고 있다.
이를 증명하기 위하여 이 논문에선 아래와 같은 작업을 수행하였다.
제한된 훈련 데이터로도 최첨단 성능으로 처음부터 물체 감지 네트워크를 훈련시킬 수있는 첫 번째 프레임워크인 DSOD를 제시하였다.
효율적인 물체 감지 네트워크를 설계하기 위해 단계별 변인 연구를 통해서 필요한 일련의 원칙을 도입하고 검증하였다.
표준 벤치 마크들을 활용하여 DSOD가 실시간 처리 속도를 보장하고 컴팩트한 모델로 높은 성능을 거둠을 증명하였다.
deep supervision은 Deeply-supervised net과 Holistically-nested edge detection에 영향을 받았다. Holistically-nested edge detection은 edge 감지를 위한 전체적인 그물망 구조를 제안하였는데, 이 구조는 Deep supervision의 각 Convolution stage에 추가 출력을 포함하는 방식이다.
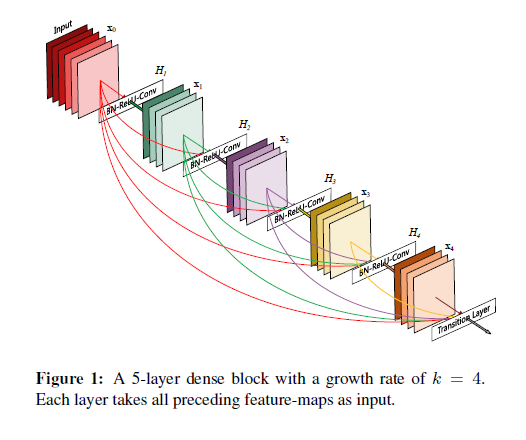
(그림1) DenseNet의 layer-wise connection
이 논문에서는다중 cut-in Loss 대신, DenseNet의 dense layer-wise connection을 사용하였다.
(그림2) 구조 비교
위의 그림은 SSD와 같은 네트워크에서 일반적으로 가지는 구조와 DSOD의 구조를 비교 한 것이다. SSD는 예측 레이어를 비대칭 모래 시계 구조로 설계하였으며, 300x300 입력 이미지의 경우 객체 예측을 위해 6가지 스케일의 피쳐 맵을 사용했다. Scale 1 피쳐 맵은 이미지의 작은 개체를 처리하기 위해 가장 큰 해상도 (38x38)를 가진 Backbone 하위 네트워크의 중간 계층에서 가져오며, 나머지 5개의 스케일은 sub-backbone 네트워크의 맨 위에 있다. 그 후, 병목 구조(피처 맵 수를 줄이기위한 1x1 conv-layer와 3x3 conv-layer)를 갖는 일반 Transition 레이어가 두 개의 연속된 피쳐 맵 스케일 사이에 사용된다. 자세한 설명은 3.1의 원칙 4에 정리하였다.
Dense 구조는 Backbone의 sub-network 뿐만 아니라 front-end 멀티 스케일 Prediction layer에서도 활용된다. 위의 그림은 front-end prediction layer의 구조 비교를 보여주며, 여기서 multi-resolution prediction-map의 융합 및 재사용은 모델 매개변수를 줄이면서 최종 정확도를 유지하거나 개선하는데 도움이 된다.
3. DSOD
3.1. DSOD Architecture
overall Framework
제안된 DSOD 방법은 SSD와 유사한 one stage 네트워크이다. DSOD의 네트워크 구조는 특징 추출을 위한 Backbone 서브 네트워크, 멀티스케일 응답 맵에 대한 예측을 위한 front-end 서브 네트워크의 두 부분으로 나눌 수 있다. Backbone 하위 네트워크는 Deeply supervise DenseNets 구조의 변형으로, stem 블록(Inception에서 제시한 앞단의 Conv 레이어), 4개의 Dense 블록, 2개의 Transition 레이어 및 풀링 없는 2개의 Transition 레이어로 구성된다. Front-ent 서브 네트워크(또는 DSOD 예측 레이어)는 정교한 Dense structure와 멀티스케일 예측 응답을 병합한다. 그림 1은 제안된 DSOD 예측 계층과 SSD에서 사용되는 멀티스케일 예측 맵의 simple structure를 보여준다. 전체 DSOD Network Architecture은 아래의 표에 자세히 설명되어 있다.
[표1] DSOD의 구조 (각 Dense 블록에 적용된 growth rate k = 48)
원칙 1: Proposal-free.
최신 CNN 기반 Object detector는 총 세가지 범주로 나눌 수 있다. 첫째, R-CNN 및 Fast R-CNN에는 Selective search와 같은 객체 영역 제안 기능이 필요하다. 둘째, Faster R-CNN 및 R-FCN은 상대적으로 적은 수의 Region proposal을 생성하기 위해 Region-Proposal-Network(RPN)를 필요로 한다. 셋째, YOLO와 SSD는 객체 위치와 경계 상자 좌표를 회귀시켜 처리하는 Single Shot 네트워크이며, 다른 범주와는 달리 Proposal이 필요 없다. 여기선 세번째 범주만이 사전 훈련되지 않은 모델로도 성공적으로 수렴할 수 있다.
그 이유는 다른 두가지 범주에는 RoI(Regions of Interest) 풀링이 존재하기 때문인데, RoI 풀링은 각 Region proposal에 대한 피쳐를 생성하여 Gradient가 Region-level에서 컨볼루션 피쳐 맵으로 원활하게 역전파되는 것을 방해한다. 또한, Proposal 방식은 사전 훈련된 네트워크 모델에서 잘 작동하는데, 이는 매개변수 초기화가 RoI 풀링 전의 계층들에 적합하지만 처음부터 훈련하는 경우에는 그렇지 않기 때문이다. 즉, 처음부터 Detection network를 훈련하려면 Proposal이 없는 프레임 워크가 필요하다. 실제로 DSOD는 SSD에서 멀티 스케일 프레임워크를 도출할 수 있다. 이는 빠른 처리 속도와 함께 높은 정확도에 도달 할 수 있기 때문이다.
원칙 2: Deep Supervision.
심층지도 학습의 효과는 GoogLeNet, DSN, DeepID3 등에서 입증되었다. 핵심 아이디어는 통합된 목적 함수를 Output Layer에서 뿐만이 아닌, 이전 Hidden Layer에 대한 직접적인 감독을 통해 제공하는 것이다. 여러 은닉 계층에서 이러한 목적 함수를 활용한 "동반하는 값"또는 "보조하는 값"은 기울기 소실 문제를 완화할 수 있다. 이 "동반 값" 목적 함수를 각 은닉 계층에 도입하기 위해선 복잡한 부차 출력 계층을 추가해야만 한다.
DSOD는 DenseNets에 소개된 dense layer-wise connection으로 심층 감독을 강화한다. 블록의 모든 선행 레이어가 현재 레이어에 연결된 경우 이 블록을 Dense 블록이라고 한다. 따라서 DenseNet의 이전 계층은 Skip Connection을 통해 목적 함수에서 추가 감독이 가능하다. 다시 말해, 네트워크 상단에는 단 하나의 손실 함수만 필요하지만 이전 계층을 포함한 모든 계층은 감독된 데이터를 공유할 수 있다.
뒤에서 서술할 풀링 레이어가 없는 Transition Layer에서 심층 감독의 이점을 확인할 수 있다. 피쳐 맵 해상도를 유지하면서 Dense 블록 수를 늘리기 위해 이 레이어(풀링 레이어가 포함되지 않은 Transition Layer)를 도입였는데, DenseNet의 원래 디자인에서 각 Transition layer에는 피쳐 맵을 다운 샘플링하는 풀링 작업이 포함되어 있다. 그 때문에 동일한 사이즈의 출력을 유지하려는 경우 Dense 블록의 수를 고정해야만 했고, 네트워크 깊이를 늘리는 유일한 방법은 DenseNet의 각 블록 내에 레이어를 추가하는 것이었다. 하지만 풀링 레이어가없는 Transition layer는 DSOD 아키텍처의 Dense 블록의 수에 대한 이러한 제약을 제거하였으며, 기존의 DenseNet에서도 사용할 수 있다.
원칙 3: Stem Block.
저자가 Inception-v3 및 v4에서 영감을 받았다는 Stem 블록을 3개의 3x3 컨볼 루션 레이어와 2x2 최대 풀링 레이어의 스택으로 정의하였다. 첫 번째 conv-layer는 stride = 2로 작동하고 다른 두 개는 stride = 1로 작동한다. 이 간단한 줄기 구조를 추가하면 실험에서 감지 성능이 반드시 향상 될 것이다. DenseNet의 원래 디자인(7x7 conv-layer, stride = 2, 3x3 max pooling, stride = 2)과 비교할 때 스템 블록은 기존 입력 이미지의 정보 손실을 줄일 수 있기 때문이라고 추측된다. 이 Stem 블록의 효과가 탐지 성능에 중요하다는 것을 뒤에서 볼 수 있다.
원칙 4: Dense Prediction Structure.
Learning Half and Reusing Half.
SSD와 같은 일반적인 구조(그림2 참조)에서 각 스케일은 인접한 이전 스케일에서 직접 전이된다. 이 논문에선 다중 스케일 정보를 융합할 수 있는 Dense structure를 제안하였다. 단순화를 위해 각 스케일의 출력이 동일한 수의 채널을 출력하도록 제한하였으며, DSOD에서 scale-1을 제외한 각 피쳐 맵의 절반은 일련의 conv-layer를 사용하여 이전 스케일에서 학습되고, 나머지 피쳐 맵은 인접한 고해상도 피쳐 맵에서 직접 다운 샘플링된다.
다운 샘플링 블록은 2x2, stride=2의 max pooling layer와 1x1, stride=1의 conv-layer로 구성한다. 풀링 계층은 해상도를 현재 크기에 맞추는 것을 연결 과정에서의 목표로 한다. 1x1 conv-layer는 채널 수를 50 %로 줄이는 데 사용된다. 풀링 레이어는 연산 비용을 절감하기 위해 1x1 conv-layer 앞에 배치된다. 이 다운 샘플링 블록은 이전의 모든 스케일에서 multi-resolution feature map을 사용하여 각 스케일을 가져 오며, 이는 본질적으로 DenseNets에 도입된 dense layer-wise connection과 동일하다. 각 스케일에서, 새로운 피쳐 맵의 절반만 학습하고 이전 피쳐 맵의 나머지 절반 을 재사용한다. 이 Dense prediction structure는 일반적인 구조보다 적은 매개변수로 더 정확한 결과를 산출 할 수 있다.
3.2. Training Settings
Caffe 프레임 워크]를 기반으로 탐지기를 구현하였음
모든 모델은 NVidia TitanX GPU에서 SGD 솔버를 사용하여 처음부터 훈련되었음
DSOD 피쳐 맵의 각 스케일은 여러 해상도에서 연결되기 때문에 L2 정규화 기술을 채택하여 모든 출력에서 피쳐의 표준을 20으로 조정하였음(SSD는이 정규화를 scale-1에만 적용하였음)
자체 Learning rate 및 미니- 배치 크기 설정을 제외한 BBOX 및 Loss Function을 포함하는 대부분의 학습 전략은 SSD를 따르며, 세부 사항은 실험 섹션에서 제공
4. Experiments
4.1. Ablation Study on PASCAL VOC 2007
[표2] 구성에 따른 DSOD의 성능 비교[표3] PASCAL VOC 2007 test set에서 진행한 실험 결과. DS/A-B-k-θ는 backbone 네트워크의 구조를 설명한다. A는 첫번째 Conv 레이어의 채널 수, B는 각 병목 레이어(1x1 conv)의 채널수, k = growth rate, θ = compression factor이다.
4.1.1. Dense Blocks의 구성
논문에선 먼저 Backbone의 하위 네트워크에 위치한 Dense 블록에서 다양한 구성의 상관관계를 조사하였다. 구성에 따른 결과는 위의 표2를 참고하면 된다.
[Transition 레이어의 압축 계수]
DenseNets의 Transition 계층에서 두 개의 압축 계수 값 (θ = 0.5, 1)을 비교한다. 결과는 표3의 2행과 3행에 나와 있다. 압축 계수 θ = 1은 Transition 레이어에서 피쳐 맵의 다운 사이징이 없음을 의미하는 반면 θ = 0.5는 피쳐 맵의 절반이 감소 함을 의미한다. 결과는 θ = 1일 때, θ = 0.5보다 2.9 % 더 높은 mAP를 달성한다는 것을 보여준다.
# 병목 레이어의 채널: 표3의 3행과 4행에서 볼 수 있듯이, 더 넓은 병목 계층(응답 맵 채널이 더 많음)이 성능을 크게 향상시키는 것으로 나타났다 (4.1 % mAP). # 첫 번째 conv-layer의 채널: 첫 번째 conv-layer에있는 많은 수의 채널이 필요하다는 것을 확인할 수 있었으며, 1.1 % mAP 향상을 가져왔다. (표의 4 행과 5 행).
[Grouth rate]
grouth rate를 나타내는 k값이 클 수록 훨씬 더 좋은 성능을 내는 것이 밝혀졌다. 4k 병목 채널에서 k를 16에서 48로 증가 시키면 표의 5행과 6행에서 4.8 % mAP 개선이 관찰되었다.
4.1.2. 디자인 원칙의 효율성 증명
[표4] PASCAL VOC 2007 test 감지 결과
[제안과정이 필요없는 프레임워크]
Faster R-CNN 및 R-FCN과 같은 제안 기반 프레임워크를 사용하여 객체 감지기를 처음부터 훈련한 프로세스는 시도한 모든 네트워크 구조(VGGNet, ResNet, DenseNet)에서 파라미터가 수렴하지 못하였다. 제안이 필요 없는 프레임워크인 SSD를 사용하여 객체 감지기를 학습 시키려고 했을 때는 학습은 성공적으로 수렴되었지만 표4에 표기된 것처럼 사전 학습 된 모델 (75.8 %)의 케이스에 비해 훨씬 더 나쁜 결과 (VGG의 경우 69.6 %)를 기록하였다. 이 실험은 Proposal-free를 활용하기 위한 설계 원칙을 검증하기 위해 시행되었다.
[Deep supervision]
논문에선 deep supervision을 통해 처음부터 물체 감지기를 훈련 시키려고 하였다. DSOD300은 77.7 % mAP를 달성하는데, 이는 VGG16 (69.6 %)을 사용하여 처음부터 훈련 된 SSD300S보다 훨씬 좋은 결과이다. 또한 SSD300 (75.8 %)의 미세 조정 결과보다 높은 결과를 보여주었다. 즉, Deep supervision의 원칙이 유효함을 입증했다고 볼 수 있다.
[풀링 레이어가 포함되지 않은 Transition] 제안된 레이어가 없는 경우(오진 3개의 Dense 블록만 존재)와 있는 경우(DSOD에서의 4개의 Dense 블록이 존재)를 비교하였다. Backbone 네트워크는 DS/32-12-16-0.5이며, 결과는 위의 표에 나와 있다. 풀링 계층이없는 Transition 블록이 있는 네트워크 구조는 1.7 %의 성능 향상을 가져와, 이 계층의 효율성을 입증하였다.
[Stem block]
표3의 6행과 9행에서 볼 수 있듯이 Stem 블록은 성능을 74.5 %에서 77.3 %로 향상시킨다. 즉 원본 이미지에서 정보 손실을 보호 할 수 있다는 추측을 입증하였다.
[Dense Prediction Structure]
속도/정확도/연산량의 세 가지 측면에서 Dense prediction 구조를 분석한다. 표4에서 볼 수 있듯이, DSOD는 추가 다운샘플링 블록의 비용으로 인해 기존 SSD보다 약간 느렸다.(17.4fps vs 20.6fps) 그러나 Dense 구조를 사용하면 mAP를 77.3 %에서 77.7 %로 개선하고 매개 변수를 18.2M에서 14.8M으로 줄일 수 있었다.(표3의 9행과 10행 참고) 또한 SSD의 예측 계층을 제안 된 Dense prediction 계층으로 교체했을 떄, 사전 학습 된 모델을 사용한 훈련에서 기존 SSD는 75.8 %에서 76.1 %로, 사용하지 않았을 때는 69.6 %에서 70.4 %로 향상 되었다. 즉, Dense prediction 레이어의 효과를 확인할 수 있었다.
[What if pre-training on ImageNet?]
pre-trained 된 ImageNet에서 하나의 light Backbone 네트워크 DS/64-12-16-1을 훈련 시켰는데, 검증 세트에서 66.8% top-1 정확도와 87.8 % top-5 정확도를 얻을 수 있었으며(VGG-16보다 약간 나쁨), “07 + 12” train val 세트에서 전체 프레임워크를 fine-tuning한 네트워크는 VOC 2007 테스트 세트에서 70.3 % mAP를 달성하였다. 이에 반해 training-from-scratch 솔루션은 70.7 %의 정확도를 달성하며 약간 더 좋은 결과를 보였다.
* 이 논문은 기존의 Convolution filter의 곱 연산을 가산(Adder)로 대체하여 연산량을 대폭 줄였으나 정확도는 유지하였다.
* 2019년 Computer Vision and Pattern Recognition 저널에 등재되었다.
* 21년 2월 23일 기준 26회 인용되었다.
1. Introduce
기존의 대부분의 Convolution Networks는 입력과 Convolution Filter 사이의 곱 연산을 통해 Weight를 업데이트 한다. 하지만 이 방식은 많은 GPU 메모리를 소모할 뿐만 아니라 많은 전력을 소비하기 때문에 휴대용 장비에서 사용하기 어렵다. 이를 보완한 MobileNet 등이 제안되어 왔지만, 곱 연산 때문에 많은 연산량이 필요하다는 점은 변하지 않았다.
이 논문에서 제안한 Adder를 활용한 네트워크는 처음 나온 아이디어가 아니다. 이진화를 활용한 binarized filter 등을 활용한 binary adder 기법들이 소개되어 왔으며, 나름 준수한 성능을 보였다. 하지만 이진화 아이디어는 기존 네트워크의 mAP를 보존할 수 없고, 수렴 속도와 학습률이 저하되는 등 훈련 절차가 안정적이지 않다. 또한, 연구원들은 기존 Convolution Filter가 익숙하고, 연산을 빠르게 만드는 기법을 도입하는 것에 익숙하다.
2. 곱셈을 포함하지 않은 네트워크
위의 그림을 보면 AdderNet과 기존 CNN과의 차별점을 쉽게 파악할 수 있다. CNN의 경우 각도로서 Class를 분류하지만, AdderNet은 군집화 된 점의 좌표를 활용하여 클래스를 분류한다. 그 이유는 CNN은 필터와 입력 간의 cross correlation을 계산하는데, 그 값들이 정규화되면 컨볼루젼 연산은 두 벡터 간의 코사인 거리를 계산하는 것과 같다. 이것이 각도로서 Classification을 하는 이유이다. 반면에 AdderNets이 $l_1 norm$을 활용하여 class를 분류하기 때문에 각각 다른 중심을 가진 포인트로 군집화 된다. 이 Visualize 결과를 봤을 때, $l_1$ distance는 심층 신경망에서 필터와 입력값 사이의 유사도로서 사용할 수 있다.
기존의 컨볼루젼 필터 F는 $F \in \mathcal{R}^{d \times d \times c_{in} \times c_{out}}$로 고려되고, 입력값은 $X \in \mathcal{R}^{H \times W \times c_{in}}$로 나타낼 수 있다. 여기서 각각 d는 필터의 커널 사이즈와 같고, $c_{in}$은 입력 채널, $c_{out}$은 출력 채널을 의미한다. H와 W는 각각 입력의 특성 값이다. 이를 활용하여 기존의 컨볼루젼의 연산은 다음과 같이 표현할 수 있다.
덧셈은 $l_1$ distance을 측정하기 위한 방법으로서 도입되었다. 뺄셈 역시 보수 코드를 활용하여 덧셈으로 통합된다. $l_1$ distance는 효율적으로 필터와 피쳐 간의 유사도를 계산할 수 있게 한다. 두 가지 모두 유사도를 계산할 수 있는 식이며, 출력값에 약간의 차이를 보인다. Conv Filter의 출력은 양수 또는 음수일 수 있지만, Adder의 출력은 항상 음수이다. 이 부분은 Batch Normalization Layer를 활용하여 정규화 함으로서 문제를 해결한다. 이 정규화 계층에도 곱셈이 포함되어 있지만 그 연산량은 Conv Layer에 비하면 한참 낮다. 결국 Convolution layer를 Adder layer로 대체함으로서 AddNets을 구성할 수 있다.
2.2. 최적화
신경망은 역전파를 사용하여 필터의 기울기를 계산하고 확률적 기울기 하강법(Stochastic gradient descent method)을 사용하여 매개변수를 업데이트한다. CNN에서 필터 F에 대한 출력 특성 Y의 편미분은 다음과 같이 계산된다.
sgn은 부호 함수를 뜻하기 때문에 기울기의 값으로 오직 +1, 0, -1만을 취할 수 있다. 그러나 위의 signSGD는 대부분의 경우 가장 가파른 기울기를 가지는 하강 방향을 취하지 않으며 차원이 커질 수록 악화되는 모습을 보인다. 즉, signSGD는 신경망 최적화에 적합하지 않다고 할 수 있다. 이러한 단점을 고려한 상태에서 여기서 $l_2-norm$을 활용한다고 생각해보자.
위의 수식은 기존 signSGD과 연결시킬 수 있는 업데이트 된 $l_2-norm$ 기울기이다. 이 식이 결국 저자가 주장한 핵심 수식이며, 이후부턴 FPG(Full-precision Gradient)라고 부르겠다.
필터의 기울기 외에도 입력 피쳐인 X 역시 매개변수 업데이트에 중요한 역할을 한다. 레이어 $i$의 필터와 입력을 $F_i, X_i$라고 했을 때, $F_i$ 자체의 기울기에만 영향을 주는 $\frac{\partial Y}{\partial F_i}$와 달리 $\frac{\partial Y}{\partial X_i}$는 기울기 연쇄법칙에 따라 $i$ 이전 레이어의 기울기에도 영향을 줄 수 있다. 이 때 위에서 제시한 FPG를 활용하여 기울기 역전파를 수행하려고 보니, 계산된 기울기 값이 [-1,1] 범위를 넘기 때문에 기울기 폭파(Gradient exploding) 현상이 발생할 수 있다는 문제가 발생한다. 이를 아래의 Hard Tanh 함수를 통해 해결할 수 있다.
일반적으로 Var[F]은 작은 값(CNN에선 $10^{-3}$ 또는 $10^{-4}$)을 가지므로 소수의 곱셈을 취하는 CNN에서의 가중치의 분산은 작아진다. 하지만 덧셈 연산을 활용하는 AdderNes에서는 대부분 CNN 대비 훨씬 더 큰 분산을 취하게 된다.
다음으로 AdderNets이 가지는 더 큰 분산의 영향을 알아보자. 활성화 함수의 효율을 높이기 위해 가산기 계층 이후에 배치 정규화 레이어를 추가한다. 미니배치 $B = \{x_1, …, x_m\}$에 대한 입력 x가 주어졌을 때 배치 정규화 계층은 다음과 같이 표현할 수 있다.
여기서 $\gamma$와 $\beta$는 학습되는 파라미터이고, $\mu_\mathcal{B} = \frac{1}{m} \sum_{i}x_i$와 $\sigma^2_\mathcal{B} = \frac{1}{m} \sum_{i} (x_i - \mu_\mathcal{B})^2$은 각각 미니배치의 평균과 분산을 표현한 수식이다. $x$에 대한 손실 $\ell$의 기울기는 다음과 같이 계산된다.
(Eq.9)에서 더 큰 분산 $Var[Y]=\sigma_\mathcal{B}$가 주어질수록 AdderNets의 X에 대한 기울기의 크기는 (Eq.11)에 따른 CNN에서의 경우보다 훨씬 작을 것이며, 연쇄법칙에 의해 AdderNets의 필터의 기울기의 크기가 감소할 것이다.(분산이 커지는 것은 데이터가 넓게 펼쳐진 정규 그래프를 이룬다는 말이며, 결국 기울기가 작아지는 것과 같다.)
위의 표는 MNIST 데이터 세트에 CNN과 AdderNets을 활용하여 LeNet-5-BN에서 $||F||_2$의 기울기의 $\ell_2$-norm을 정리한 표이다. BN은 배치 정규화 계층을 추가했다는 뜻이며, 첫번째 iteration에서의 결과를 토대로 작성되었다. 이 표에서 볼 수 있듯이 AdderNets의 필터의 기울기 값이 CNN의 경우보다 훨씬 작기 때문에 업데이트 속도가 느리다. 이를 보완하기 위해 더 큰 학습률을 채택하면 될 듯 싶지만, 표에서 볼 수 있듯이 기울기의 norm 값은 계층마다 크게 달라지는 모습을 보이고, 이에 따라 필터의 특성을 고려한 학습률 선택이 필요하단걸 알 수 있다. 때문에 제안된 Adaptive Learning Rate(ALR)는 아래와 같다.
여기서 $\gamma$는 Local 학습률(가산기와 BN에 적용되는 값과 같음)이고, $\Delta L(F_l)$은 레이어 $l$의 필터의 기울기이며, $\alpha_l$은 Local 학습률(해당 레이어에만 적용)이다. AdderNets에서 필터는 입력과의 차이를 계산하므로 그 크기는 입력에서 의미있는 정보를 추출하는 데에 더 적합하다. 배치 정규화 레이어로 인해 서로 다른 계층의 입력 크기가 정규화되며, 서로 다른 계층의 필터 크기에 대한 정규화가 이루어진다. 따라서 Local 학습률은 다음과 같이 정의할 수 있다.
k는 $\ell_2$-norm을 평균화하기 위해 사용되는 $F_l$의 요소 수를 나타내며, $\eta$는 가산기 필터의 학습률을 제어하는 하이퍼 파라미터이다. 제안된 Adaptive Learning Rate 스케일링을 활용하면 서로 다른 계층의 가산기 필터를 거의 동일한 단계로 업데이트 할 수 있다.
정리하면 알고리즘은 다음과 같다.
- Algoritm is repeated for (convergence):
Input:초기화 된 가산 네트워크$\mathcal{N}$, 트레이닝 세트$\mathcal{X}$, 해당하는 라벨 $\mathcal{Y}$, global 학습률 $\gamma$, 하이퍼 파라미터 $\eta$
이 논문에선 MNIST, CIFAR 및 ImageNet을 포함한 여러 벤치마크 데이터셋에서 AdderNet의 효과를 검증하기 위한 실험을 구현하였다. 이와 관련된 Ablation study(머신러닝에서 구성 레이어를 제거하였을 때의 전체 성능에 미치는 영향에 대한 통찰을 얻기 위한 실험) 및 특징 시각화가 이 섹션에 삽입되었다. 실험은 Pytorch 환경에서 NVIDIA Tesla V100 GPU를 활용하여 진행되었다.
3.1. Experiment on CIFAR
위의 표는 32x32 RGB 컬러 이미지로 구성된 CIFAR-10와 CIFAR-100 데이터셋의 Classification 결과이다. 초기 학습률은 0.1로 설정하였으며, polynomial learning rate schedule(keras 내부 함수)을 따랐다. 모델은 400 epochs 동안 256개의 배치 사이즈로 나뉘어 훈련되었다. AdderNets은 곱셈없이 CNN과 거의 비슷한 결과를 달성했지만 XNOR 연산을 활용한 BNN(Binary Neural Network)의 경우는 모델 크기는 오히려 AdderNets보다도 작지만 정확도가 훨씬 떨어진다. ResNet20에서 CNN이 역시 가장 좋은 결과를 보이지만 곱셈이 많이 포함되어 연산량이 가장 많으며, ResNet32에서는 AdderNets와 거의 성능 차이가 없는 모습을 보인다.
3.2. Experiment on ImageNet
224x224 RGB걸러의 이미지로 구성된 ImageNet의 데이터셋에 대한 실험 결과이다. ResNet-18을 사용하여 평가되었으며, 코사인 학습률 감소법을 활용하여 150 epochs 동안 훈련하였다. 네트워크들은 NAG(Nesterov Accelerated Gradient)를 사용하여 최적화 되었으며 가중치 감소와 모멘텀은 각각 $10^{-4}$와 0.9로 설정되었다. 배치 사이즈는 256을 사용하였고, 나머지 하이퍼 파라미터들은 CIFAR 데이터셋 실험과 같게 적용되었다. 실험 결과 ResNet-18에선 BNN은 낮은 정확도를 보였으나, 상대적으로 AdderNets은 높은 정확도를 보였으며, ResNet-50으로 구성된 네트워크에선 CNN과 비슷한 성능을 냄을 볼 수 있다.
3.3. Visualization Results
3.3.1. Filters
필터를 볼 때 AdderNets과 CNN의 유사성을 볼 수 있는데, LeNet-BN 네트워크 필터를 시각화한 위의 사진에서 AdderNets과 CNN은 다른 metric을 사용함에도 필터의 패턴이 비슷한 것을 볼 수 있다. 결국, 곱셈없이 덧셈으로만 저비용으로 고효율을 낼 수 있다.
3.3.2. weights
AdderNets(좌측)과 CNN(우측)에 대한 가중치 히스토그램
위의 그림에서, AdderNets은 Laplace 분포에 가깝고 CNN은 가우시안 분포에 가까워 보인다. 실제로 $\ell_1$-norm은 Laplace 분포를 따르고, $\ell_2$-norm은 Gaussian 분포를 따른다.
3.4. Ablation study
이 섹션에선 가산 필터를 사용하여 AdderNets의 여러 계층을 처리하기 위한 적응형 학습률 스케일링을 설계하는 과정을 설명하였다. 먼저 학습률을 변경하지 않았을 때, LeNet-5-BN을 훈련시키고 FPG와 Sine Gradient를 사용하여 54.91% 및 29.26의 정확도를 얻었다. 기울기가 매우 작기 때문에 네트워크를 거의 훈련할 수 없었으며, 학습률을 상향할 필요가 있었다. 가산기 필터의 학습률을 100만큼 증가시키고 FPG를 사용하여, 풀 [10, 50, 100, 200, 500]의 다른 값과 비교하며 최고의 성능을 달성할 수 있었다. 아래 그림에서 적응형 학습률(Adaptive Learning Rate, 이하 ALR) 및 증가된 학습률(Increased Leraning Rate, 이하 ILR)을 사용하는 AdderNets은 Sign Gradient를 활용하여 97.99% 및 97.72%의 정확도를 달성하였지만 CNN의 정확도(99.40%)엔 미치지 못했다. AdderNets에서 ILR을 활용한 AdderNets은 FPG를 사용하였을 때 98.99%의 정확도를 달성하였으며, ALR을 활용했을 때는 99.40%의 정확도를 달성하였다. 즉, ALR이 더욱 효과적이었다.
4. Conclusions
이 논문에서 얻을 수 있는 것은 연산량이 많은 곱셈 방식을 가산기로 대체 할 수 있다는 가능성이다. 실제로 논문에선 가산기를 활용한 CNN의 성능과 유사한 성능에 도달하였으며 Full Precision Gradient 기법을 제안하였다. 특히, Adaptive Learning Rate를 도입하여 FPG의 문제점을 해결한 부분 역시 인상적이었다. 연산량을 줄여 알고리즘의 처리속도를 빠르게 할 수 있다면, 기존 FPS와 mAP가 반비례하는 성질을 해소하여 실시간 처리가 필요한(특히 자율주행) 분야에 큰 도움이 될 수 있을것이라 생각한다. 하지만 실험에서 사용한 이미지들의 크기가 작은 것으로 보아 큰 사이즈의 이미지를 처리하는 RCNN류 등의 알고리즘에도 성능 저하 없이 적용할 수 있는지는 검증이 필요하다.
5. Reference
Chen, Hanting, et al. "AdderNet: Do we really need multiplications in deep learning?." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
- 하지만 이 GIoU는 수렴 속도가 느리고 부정확한 회귀를 한다는 문제점을 여전히 가지고 있다. 저자는 이를 해결하기 위해 DIoU를 제시한다.
GIoU의 수렴 과정
- 그림은 GIoU의 수렴 과정을 시각화 한 자료이며 검은 박스가 첫 Detection, 초록 박스가 수렴해야 할 Ground Truth, 파란 박스가 이전 과정에서 수렴한 박스(훈련 중인 박스)를 의미한다. 그림에서 볼 수 있듯이 GIoU의 수렴 속도를 느리게 하는 주요 원인은 박스의 수렴 방식에 있다. 박스는 Ground Truth로 이동하는 모습이 아니라, 박스를 키워 Ground Truth와 겹쳐진 후에 Ground Truth와 완전히 겹쳐지는 과정을 거친다. 여기서 박스의 위치와 스케일 수렴이 따로 이루어진다고 생각할 수 있다.(박스의 크기가 바뀌고 GT와 겹쳐지기까지의 과정이 Location 수렴이라고 생각하면 겹쳐진 후 박스의 크기와 중심을 GT에 맞추는 과정이 Scale 수렴이라고 볼 수 있다.)
DIoU의 수렴 과정
- 하지만 DIoU의 경우 박스 간의 거리(중심점 간의 거리) 역시 파라미터로 도입하여 Scale의 변화가 크지 않고 상대적으로 빠르게 Ground Truth와 겹쳐지는 모습을 보인다. GIoU의 경우 400회에도 완전히 수렴하지 못했지만, DIoU는 120회만에 BBOX가 수렴한 모습을 볼 수 있다.
케이스별 IoU/GIoU/DIoU 비교
- 위의 그림이 수렴 속도를 느리게 하는 가장 큰 원인인데, 박스 두 개가 겹쳐있는 경우엔 GIoU에서 도입한 C 영역은 A와 B의 합집합의 크기와 같아지고, 결국 기존 IoU와 같은 값을 갖는다. 즉, 박스가 떨어져 있는 경우에 집중했던 GIoU는 박스가 겹쳐있는 경우까지는 고려하지 못한 방식이다.
- 이 논문에서는 중심점 간의 거리를 파라미터로 도입한 DIoU를 사용하였고, 위의 그림에서도 각각 다른 값을 갖는 모습을 보여준다.(여기서 세 번째 그림에서 DIoU 역시 완전히 수렴하지 않았음에도 IoU와 같아지는 문제를 보이는데 이는 뒤에 나올 CIoU로 해결이 가능하다.)
2. Related work
2.1 IoU와 GIoU의 Loss 분석
- 원래는 IoU의 손실과 원래는 IoU의 손실과 GIoU의 손실의 한계를 분석하는 것이 필요하다. 그러나 회귀 과정에선 다양한 다른 거리, 척도, 종횡비 등의 요소가 반영된다. 이러한 변인이 통제되지 않고 포괄적이지 않은 벤치마크의 회귀 과정의 경우, Detection 결과에서 BBOX 회귀 절차를 분석하는 것은 매우 어렵다. 이를 위해 저자는 회귀 사례를 종합적으로 고려하여 주어진 손실 함수의 문제점을 쉽게 분석할 수 있는 시뮬레이션 실험을 수행하였다.
2.2 Simulation
Simulation 구조, 1,715,000개의 시나리오가 존재
-이 실험에선 그림과 같이 거리, 스케일, 종횡비를 모두 고려하여 BBOX 간의 관계를 다룬다. 위의 그림을 참고하면 이해가 편하다.
〈Simulation 환경 구성〉
1. 타겟 BBOX는 7개의 비율(1:4, 1:3, 1:2, 1:1, 2:1, 3:1, 4:1)을 갖고 넓이가 1인 앵커 박스를 가진다.
2. 7개의 타겟 박스의 중심점은 (10,10)에 고정된다.
3-1 거리: 앵커 박스는 5,000개의 지점에 균일하게 흩어져 있다.
3-2 배율: 각 점마다 존재하는 앵커 박스의 넓이는 0.5, 0.67, 0.75, 1, 1.33, 1.5, 2로 설정된다.
3-3 종횡비: 특정 점 및 배율에 대해 7가지의 종횡비를 사용한다.(이는 타겟 박스와 같다)
4. 모든 5,000x7x7개의 앵커 박스는 loss function에 의해 각각의 타겟 박스에 딱 맞도록 이동한다.
요약하면, 시뮬레이션에는 1,715,000(7x7x7x5,000)개의 회귀 시나리오가 있다고 할 수 있다. 주어진 손실 함수 $L$에 의해 각각의 케이스에서 경사하강법(Gradient decent Algorithm) BBOX 회귀를 시뮬레이션 할 수 있다.
예측된 박스 \(B^t_i\)에서 $t$는 반복 횟수를 뜻하고, $\nabla B%{t-1}_i$는 $t-1$번째에 대한 기울기 손실을 의미하며 $\eta$는 step을 의미한다. 여기서 주목할만한 점은 $2 - IOU^{t-1}_i$를 기울기에 곱하여 수렴 속도를 더 빠르게 했다는 점이다.
BBOX 회귀는 $l_1-norm$에 의해 평가되며, 각각의 손실 함수를 사용한 시뮬레이션은 t=200까지 진행되었으며, error 그래프(Loss의 수렴 결과)는 위의 그림과 같다.
- 이 그림을 보면 IoU는 박스가 겹친 경우에만 수렴하는 모습을, GIoU는 모두 수렴은 하지만 그 속도가 느린 모습을 보인다. 하지만 DIoU의 경우는 빠르게 수렴하는 것을 볼 수 있다.
- 실제로 GIoU의 경우 $|C - A \cup B|$를 패널티로 활용하지만 그 넓이가 가끔 너무 작거나 0인 경우가 존재한다. 이런 케이스에선 GIoU의 영향력은 낮거나 없는 것과 같기 떄문에 수렴 속도가 매우 느린 모습을 보인다.
- 저자는 이 수렴 속도를 증가시키기 위하여 두 상자 간의 거리 값도 패널티로 주는 방향으로 설계된 DIoU를 제시하였고, 실제로 더 정확하고 빠른 회귀를 보였다.
3. 제안된 알고리즘(DIoU/CIoU)
3.1 Distance IoU
논문에서 제시한 DIoU 손실함수의 구조는 아래와 같다.
$\mathcal{L} = 1 - IoU + \mathcal{R}(B, B^{gt})$
- 여기서 1 - IoU 부분은 기존의 IoU를 활용한 손실 함수와 동일하고, $\mathcal{R}$로 묶인 항은 새롭게 정의된 패널티항으로 볼 수 있다. 이 부분은 GIoU와 DIoU, CIoU가 모두 다른데, DIoU의 경우, 아래와 같이 정의할 수 있다.
- $\rho$는 유클리드 거리를 뜻하고, $b$와 $b^{gt}$는 BBOX들의 중점이다. c는 GIoU에서 정의한 두 박스를 최소의 크기로 감쌀 수 있는 C박스의 대각선 거리이다.(아래 그림 참고)
GT 박스와 Deteced 박스, 그리고 C박스
· DIoU의 특징은 다음과 같다.
1. 스케일에 영향을 받지 않는다.
2. GIoU와 비슷하게 박스가 겹치지 않아도 겹치도록 수렴한다.
3. 두 박스가 완전히 겹쳤을 때는 $\mathcal{L}_{IoU} = \mathcal{L}_{GIoU} = \mathcal{L}_{DIoU} = 0$이고, 두 박스가 완전히 겹치지 않았을 때는 $\mathcal{L}_{GIoU} = \mathcal{L}_{DIoU} = 2$이다.
4. 하지만 DIoU 손실은 박스가 겹치도록 빠르게 수렴하는 모습을 보인다.
5. $|C - A \cup B| = 0$인 상황일 때도 GIoU와 달리 DIoU는 빠르게 수렴할 수 있다.
3.2 Complete IoU
그렇다면 Complete IoU(CIoU)란 무엇일까? CIoU는 아래와 같은 식으로 표현된다.
여기서 $\omega$와 $h$ 값이 0과 1사이에 존재 할 때는 $\omega^2 + h^2$ 값이 너무 작아져서 기울기 폭발(gradient explosion)이 발생할 수 있다. 이를 방지하기 위하여 $\frac{1}{\omega^2 + h^2} = 1$로 대체하여 간단히 위험 요소를 제거할 수 있다. 이 작업을 거치더라도 기울기 수렴 방향은 불변한다.
3.3 Distance IoU를 접목시킨 Non-Maximum Suppression
- 이 아이디어는 NMS 알고리즘에도 접목시킬 수 있는데, 기존의 방식은 IoU를 활용하기 때문에 Occlusion(가림)이 발생한 경우에 올바른 박스가 삭제되는 문제가 발생한다. 이에 DIoU를 병합하는 것은 굉장히 간단하다. 기존 IoU로 점수를 계산하던 부분에 $\mathcal{R}_{DIoU}$항을 추가하면 되기 때문이다.
Zheng, Zhaohui, et al. "Distance-IoU loss: Faster and better learning for bounding box regression." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.
이 논문은 Loss function의 파라미터 자체를 IoU로 변경하여 기존 딥러닝 네트워크의 추가적인 성능 향상을 목표로 한 논문이다. 19년 CVPR에서 소개된 논문임에도 불구하고 현재(21년 2월 17일) 기준 인용수가 366회에 달할 정도로 주목을 받은 논문이라고 할 수 있다.
논문에 대한 리뷰에 앞서, matlab에서 직접 작성한 GIOU를 계산하기 위한 코드를 첨부한다.
function [giou,iou] = gIoU(bboxes1, bboxes2)
% Reference : Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
% Calculate generalized Intersection over Union
% define point of first bounding boxes.
x1p = bboxes1(:,1);
x2p = bboxes1(:,1) + bboxes1(:,3);
y1p = bboxes1(:,2);
y2p = bboxes1(:,2) + bboxes1(:,4);
% define point of second bounding boxes.
x1g = bboxes2(:,1);
x2g = bboxes2(:,1) + bboxes2(:,3);
y1g = bboxes2(:,2);
y2g = bboxes2(:,2) + bboxes2(:,4);
% Calculate Area of Bboxes1&2
area_1 = (x2p - x1p) .* (y2p - y1p);
area_2 = (x2g - x1g) .* (y2g - y1g);
%cal intersection
IoU_min = bboxOverlapRatio(bboxes1,bboxes2, 'Min');
Overlap = IoU_min .* min(area_1, area_2');
All_Area = (max(x2p, x2g') - min(x1p,x1g')).*(max(y2p,y2g') - min(y1p,y1g'));
C_boxes = (All_Area - (area_1+area_2'-Overlap))./All_Area;
iou = bboxOverlapRatio(bboxes1, bboxes2);
giou = iou - C_boxes;
end
Matlab에서 위의 코드로 GIoU를 계산할 수 있다.
1. Introduce
2D 이미지 분야에서 딥러닝 네트워크를 학습 시킬 때 최종적인 목표는 Ground Truth를 Prediction이 완벽하게 추종하는 것이다. 즉, IoU(Intersection over union)이 1이 되는것을 목표로 한다. 하지만 대다수의 최신 네트워크들은 IoU를 향상시키기 위해서 x, y, w, h라는 파라미터를 활용한 학습을 진행한다. 하지만 ln loss를 최소화 하는 것과 IoU 값을 개선하는 것 사이에는 큰 관련이 없다는 문제가 존재한다.
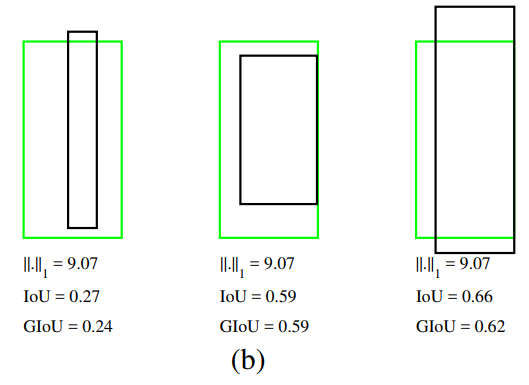
각 케이스별 l2 loss/IoU/GIoU 비교
위의 그림에서 두 상자의 좌측 하단 모서리를 고정하고, 검은 상자(여기서는 Prediction이라 가정하자)의 우측 상단 모서리가 회색 점선으로 그려진 원 위에 존재할 때, 모든 경우에서 l2 loss는 같다. 하지만 IoU와 GIoU는 다른 값을 갖고, 우리의 최종 목표인 완벽하게 포개지는 박스를 예측하는 것(IoU = 1)에도 영향을 주지 않는다.
각 케이스별 l1 loss/IoU/GIoU 비교
그렇다면 l1 loss는 다를까? 딥러닝에선 잘 사용하지는 않지만(Overfitting의 위험성 등 때문) 이 경우에도 비교해보면 세 경우에서 l1 loss가 일정할 때, IoU와 GIoU가 다르게 계산된다.
위와 같은 이유 때문에 저자는 여기서 IoU를 Loss function의 파라미터로서 도입했을 때 직접적인 성능 향상이 가능할 것이라고 예측했다.
2. Related works
하지만 IoU를 훈련에 활용하기 앞서 문제가 있는데, 바로 박스가 떨어졌을 때 그 문제가 발생한다.
A: Ground Truth / B: Prediction
그림에서 볼 수 있듯, 예측된 박스가 Ground Truth와 조금이라도 겹친 경우에는 훈련에 활용할 수 있지만, 겹치지 않은 경우 박스가 얼마나 떨어졌는지 판단할 근거가 존재하지 않는다. 즉, Loss = 1 - IoU로 훈련한다고 가정하면 박스가 떨어져있는 경우에는 Loss가 1이 되고 Gradient exploding이 발생할 것을 예측할 수 있다.
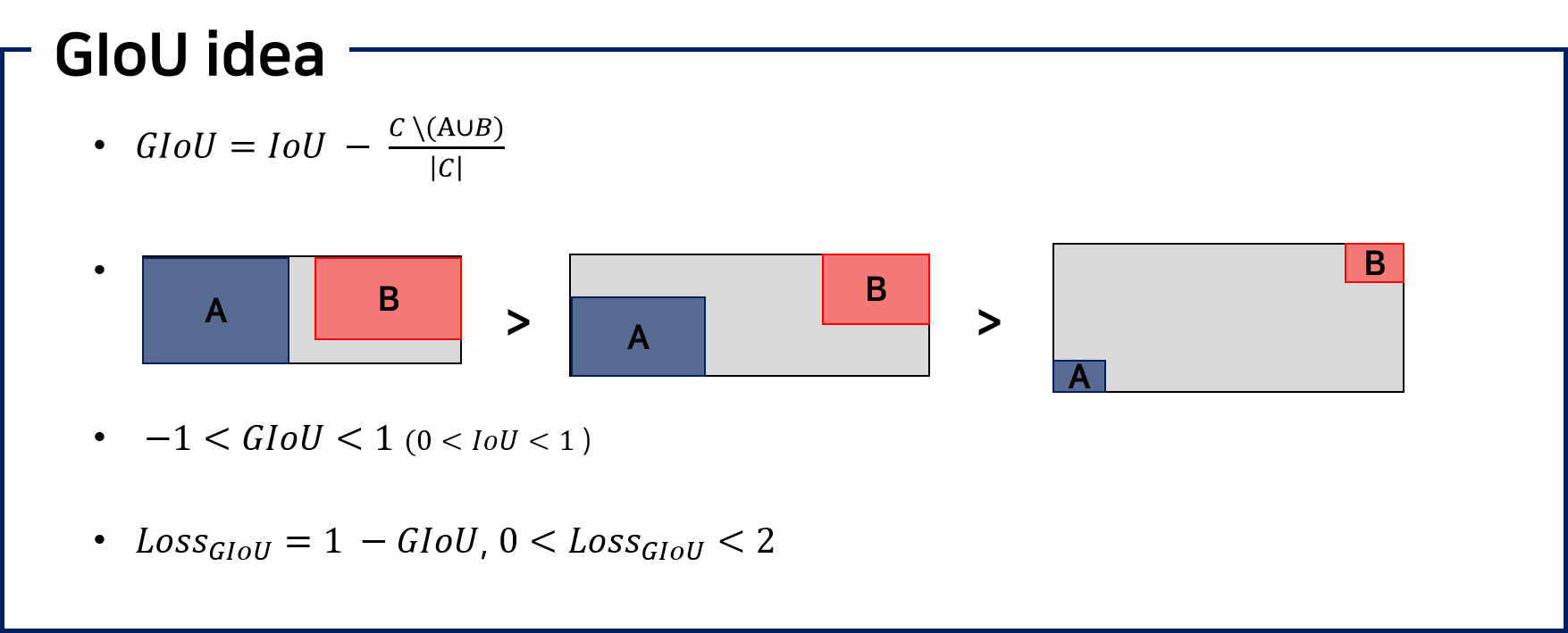
3. Generalized Intersection over Union
주저리주저리
드디어 본론이다. 논문에서는 GIOU를 계산하는 알고리즘 두 가지(한 가지는 세부적인 설명)을 제시하며 주저리주저리 설명하지만 이를 간단히 그림으로 설명하면,
GIoU를 이해하기 쉽게 그림으로 표현해봤다.
A와 B 영역을 모두 감쌀 수 있는 최소 영역인 C를 만들고, C를 활용하여 A와 B가 얼마나 떨어져 있는지에 대해 반영할 수 있는 추가 항을 도입한다. 처음의 공식을 보면 기존 IoU에서 전체에서 회색 공간이 차지하는 비율을 뺀 값을 GIoU로 설정한 것을 볼 수 있다. 이 때문에 회색 공간의 비율이 IoU보다 크게되면 GIoU는 음수를 가질 수 있다는 특징이 있다.
GIoU는 -1부터 1 사이의 값을 같게 된다는 것과 두 박스가 얼마나 떨어졌는지를 반영할 수 있다는 점이 기존 IoU와의 가장 큰 차별점이다. 하지만 두 박스가 완전히 겹친 경우(즉, 학습을 더이상 할 필요가 없는 경우) 1의 값을 가진다는 부분에서는 유사하다.
저자가 처음 제시했던 Loss = 1 - IoU를 수정하여 Loss = 1 - GIoU로 설정하면 박스가 멀어져도 훈련이 가능하고, 박스가 겹친 경우 더이상 훈련되지 않는 시스템을 갖출 수 있다.
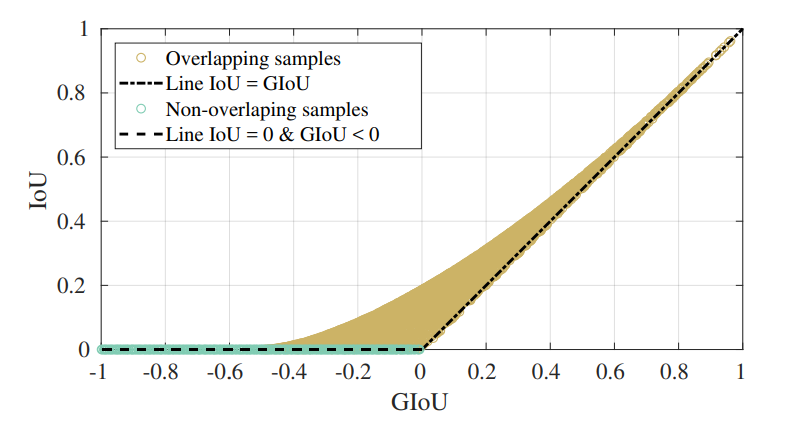
그래프를 보면 초록색으로 표시된 부분(겹치지 않은 박스 샘플)의 IoU 값은 0으로 일정하지만, GIoU 값은 음수로서 계산되는 모습을 볼 수 있다. GIoU를 활용하면 이 부분에 찍힌 점들을 모두 학습 가능하다는 이야기.
4. Experimental Results
실험 결과는 당연히 GIoU Loss를 활용했을 경우가 기존 MSE나 L1 smooth 를 활용한 경우보다 향상되었다. 이 논문에서는 YOLO v3, Faster R-CNN, Mask R-CNN에 대한 실험을 진행하였고, YOLO v3에선 상대적으로 큰 향상이 이루어졌다.(2014 validation set of MS COCO기준 AP75 9.78% 향상)
이는 R-CNN 계열에서 Anchor Box 개념을 도입하였고, 상대적으로 촘촘하고 정교한 앵커 박스들을 활용했기 때문으로 짐작한다.